Gpu
基本知识
在 AI 算力建设中, RDMA 技术是支持高吞吐、低延迟网络通信的关键。目前,RDMA技术主要通过两种方案实现:Infiniband和RoCE(基于RDMA的以太网技术,以下简称为RoCE)。
InfiniBand 无限带宽
InfiniBand架构是一种支持多并发链接的“转换线缆”技术,它是新一代服务器硬件平台的I/O标准。 由于它具有高带宽、低延时、 高可扩展性的特点,它非常适用于服务器与服务器(比如复制,分布式工作等),服务器和存储设备(比如SAN和直接存储附件)以及服务器和网络之间(比如LAN, WANs和the Internet)的通信 。
InfiniBand采用以应用程序为中心的消息传递方法,找到从一个点到另一个点传递数据的阻力最小的路径。 这与传统的网络协议(如TCP/IP和光纤通道)不同,后者使用更以网络为中心的方法进行通信。
由于InfiniBand提供了基于credit的流控制(其中发送方节点发送的数据不会超过链路另一端的接收缓冲区公布的“credit”量),传输层不需要像TCP窗口算法那样的丢包机制来确定最佳的正在传输的数据包数量。 这使得高效的产品能够以极低的延迟和可忽略的CPU使用率为应用程序提供56 GB/s的数据速率。
IB( Infiniband 协议)

- 物理层定义了在线路上如何将比特信号组 成符号,然后再组成帧、 数据符号以及包之间的数据填 充等,详细说明了构建有效包的信令协议等;
- 链路层定义了数据包的格式以及数据包操作的协议,如流控、 路由选择、 编码、解码等;网络层通过在数据包上添加一个40字节的全局的路由报头(Global Route Header,GRH)来进行路由的选择,对数据进行转发。在转发的过程中,路由 器仅仅进行可变的CRC校验,这样就保证了端到端的数据传输的完整性;
- 传输层再将数据包传送到某个指定 的队列偶(QueuePair,QP)中,并指示QP如何处理该数据 包以及当信息的数据净核部分大于通道的最大传输单 元MTU时,对数据进行分段和重组。
InfiniBand 的速度与以太网相比如何?
答:与传统以太网相比,InfiniBand的速度要高得多。以太网的运行速度通常为 1Gbps、10Gbps或100Gbps,而InfiniBand可以提供高达200Gbps 甚至更高的速度。
NVLink
NVLink是为了解决服务器内部GPU之间点到点通讯的一种协议. NVLink主要目的是为GPU互联提供一个高速和点对点的网络,对比传统网络不会有例如端到端报文重传,自适应路由,报文重组等开销.
NVSwitch芯片是一种类似交换机ASIC的物理芯片,通过NVLink接口可以将多个GPU高速互联到一起,从而提升服务器内部多个GPU之间的通讯效率和带宽.
NVLink服务器指的是采用NVLink和NVSwitch技术来互联GPU的服务器,
DMA( Direct Memory Access 直接内存访问)

DMA 是单机内存和设备间数据传输的“发动机”。 它的核心目标是加速设备(如硬盘、显卡、网卡)与本地内存之间的数据流动,减少 CPU 的参与.
红线部分为传统内存访问,需要通过CPU进行数据copy来移动数据,通过CPU将内存中的Buffer1移动到Buffer2中。 在DMA模式:可以同DMA Engine之间通过硬件将数据从Buffer1移动到Buffer2,而不需要操作系统CPU的参与,大大降低了CPU Copy的开销。
DMA 传输过程

1、DMA请求
CPU对DMA控制器初始化,并向I/O接口发出操作命令,I/O接口提出DMA请求。
2、DMA响应
DMA控制器对DMA请求判别优先级及屏蔽,向总线裁决逻辑提出总线请求。
当CPU执行完当前总线周期即可释放总线控制权。此时,总线裁决逻辑输出总线应答,表示DMA已经响应,通过DMA控制器通知I/O接口开始DMA传输。
3、DMA传输
DMA控制器获得总线控制权后,CPU即刻挂起或只执行内部操作,由DMA控制器输出读写命令,直接控制RAM与I/O接口进行DMA传输。 在DMA控制器的控制下,在存储器和外部设备之间直接进行数据传送,在传送过程中不需要中央处理器的参与。开始时需提供要传送的数据的起始位置和数据长度。
4、DMA结束
当完成规定的成批数据传送后,DMA控制器即释放总线控制权,并向I/O接口发出结束信号。
当I/O接口收到结束信号后,一方面停 止I/O设备的工作,另一方面向CPU提出中断请求,使CPU从不介入的状态解脱,并执行一段检查本次DMA传输操作正确性的代码。
RDMA(Remote Direct Memory Access 全称远端内存直接访问技术)
RDMA 是分布式网络环境的“整车”。 它不仅继承了 DMA 的核心能力,还扩展到了网络通信范畴,提供了远程节点间的高效、零拷贝通信。

https://github.com/linux-rdma/rdma-core: 用于RDMA(远程直接内存访问)通信的用户空间库和工具. rdma-core项目的核心组件是libibverbs库,它提供了一个编程接口,使应用程序能够与RDMA适配器进行交互和通信。 libibverbs提供了对RDMA传输层(RDMA Transport)的抽象,支持多种RDMA传输层协议,如InfiniBand和RoCE(RDMA over Converged Ethernet)。 除了libibverbs之外,rdma-core还提供了其他工具和库,包括librdmacm用于管理RDMA连接、libibumad用于管理InfiniBand子网管理器(Subnet Manager)、ibvtools用于诊断和调试RDMA设备等。这些工具和库一起构成了一个完整的RDMA开发和管理的工具集。
# rdma 设备查看 , 安装 yum install libibverbs-utils
$ ibv_devinfo -d mlx5_192
hca_id: mlx5_192
transport: InfiniBand (0)
fw_ver: 16.26.2002
node_guid: 0000:0000:0000:0000
sys_image_guid: 8c2a:8e03:00d4:8110
vendor_id: 0x02c9
vendor_part_id: 4120
hw_ver: 0x0
board_id: HUA0000000024
phys_port_cnt: 1
port: 1
state: PORT_DOWN (1)
max_mtu: 4096 (5)
active_mtu: 1024 (3)
sm_lid: 0
port_lid: 0
port_lmc: 0x00
link_layer: Ethernet
RoCE (RDMA over Converged Ethernet 基于融合以太网的RDMA)
为什么我们有了Infiniband协议之后,还要设计RoCE协议呢?最主要的原因还是成本问题:由于Infiniband协议本身定义了一套全新的层次架构,从链路层到传输层,都无法与现有的以太网设备兼容。 也就是说,如果某个数据中心因为性能瓶颈,想要把数据交换方式从以太网切换到Infiniband技术,那么需要购买全套的Infiniband设备,包括网卡、线缆、交换机和路由器等等

RoCEv1中,以太网替代了IB的链路层(交换机需要支持PFC等流控技术,在物理层保证可靠传输),然而,由于RoCEv1中使用的是L2 Ethernet网络,依赖于以太网的MAC地址和VLAN标签进行通信,而不涉及网络层(IP层,即OSI模型的第三层)的路由功能,因此,RoCE v1数据包不能实现跨不同的IP子网传输,只能在同一广播域或L2子网内进行传输。
RoCEv2在RoCEv1的基础上,融合以太网网络层,IP又替代了IB的网络层,因此也称为IP routable RoCE,使得RoCE v2协议数据包可以在第3层进行路由,可扩展性更优。
网络层级对比
- 在物理层,RoCE和IB都支持800G,但PAM4相比NRZ具有更强的升级潜力,以太网成本也低于IB,RoCE更胜一筹。
- 在链路层,两者均实现了无损传输,RoCE的ETS能够为不同优先的流量提供带宽保证,且RoCE和IB的时延均达到了100ns级别,在实际应用中差不大。
- 在网络层,RoCE借助IP的成熟的持续发展,更能适应大规模网络。
- 传输层及以上,RoCE和IB使用同样的协议,没有区别。
内存的架构

系统存储:
- L1/L2/L3:多级缓存,其位置一般在CPU芯片内部;
- System DRAM:片外内存,内存条;
- Disk/Buffer:外部存储,如磁盘或者固态硬盘。
GPU设备存储:
- L1/L2 cache:多级缓存,其位置在GPU芯片内部;
- GPU DRAM:通常所指的显存
传输通道:
- PCIE BUS:PCIE标准的数据通道,数据就是通过该通道从显卡到达主机;
- BUS: 总线。计算机内部各个存储之间交互数据的通道;
- PCIE-to-PCIE:显卡之间通过PCIE直接传输数据;
- NVLINK:显卡之间的一种专用的数据传输通道,由NVIDIA公司推出
GPU是如何做计算

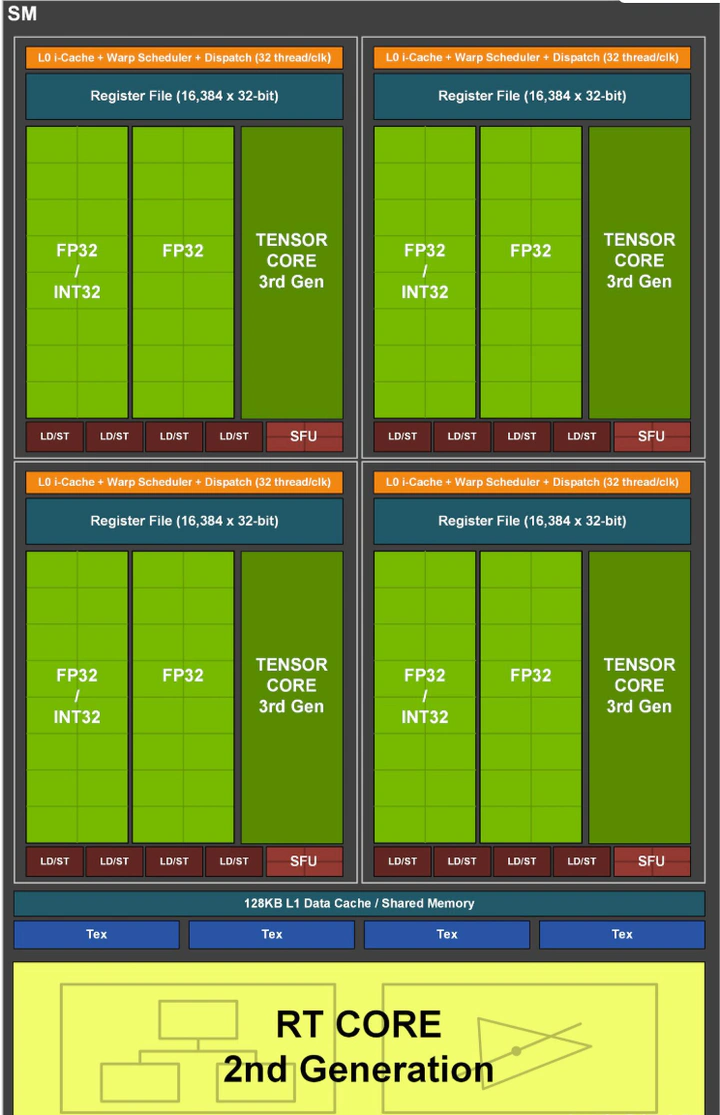
负责GPU计算的一个核心组件叫SM(Streaming Multiprocessors,流式多处理器),可以将其理解成GPU的计算单元,一个SM又可以由若干个SMP(SM Partition)组成,例如图中就由4个SMP组成。 SM就好比CPU中的一个核,但不同的是一个CPU核一般运行一个线程,但是一个SM却可以运行多个轻量级线程(由Warp Scheduler控制,一个Warp Scheduler会抓一束线程(32个)放入cuda core(图中绿色小块)中进行计算)。
GPU 内存管理

对GPU内存的使用经历了三个阶段,
第一个阶段是分离内存管理,GPU上运行的Kernel代码不能直接访问CPU内存,在载入Kernel之前或Kernel执行结束之后必须进行显式的拷贝操作;
第二个阶段是半分离内存管理,Kernel代码能够直接用指针寻址到整个系统中的内存资源;
第三个阶段是分离内存管理,CPU还是GPU上的代码都可以使用指针直接访问到系统中的任意内存资源。
分离内存管理
- 页锁定内存(Page-locked Memory),或称固定内存(Pinned Memory)和零拷贝内存.
将数据在系统内存中锁住,避免数据在系统环境切换(如线程更换)时,数据从内存转移到硬盘。
- 所谓零拷贝,就是GPU寄存器堆直接与主机内存交互。从代码里可以看到,将主机内存指针进行映射后,Kernel就可以直接使用指针来访问主机内存了,读取的数据会直接写入寄存器中. 具体的做法是,直接申请pinned memory,然后将指针传递给运算的kernel:
UVA (Unified Virtual Address 半分离内存管理)
UM (Unified Memory 统一内存管理)
nvidia-smi(NVIDIA System Management Interface)
nvidia-smi 调用的是 NVML。NVML 全称是 NVIDIA Management Library,提供了一组 C API,用于 NVIDIA GPU 监控和管理的库。