RAG 检索增强生成
Sep 5, 2025
·
1 min read
Retrieval-Augmented Generation,即检索增强生成,它结合了检索和生成的能力,为文本序列生成任务引入外部知识。
RAG 将传统的语言生成模型与大规模的外部知识库相结合,使模型在生成响应或文本时可以动态地从这些知识库中检索相关信息。
RAG 的工作原理

RAG 的工作原理可以概括为几个步骤。
- 检索:对于给定的输入(问题),模型首先使用检索系统从大型文档集合中查找相关的文档或段落。这个检索系统通常基于密集向量搜索,例如 ChromaDB、Faiss 这样的向量数据库。
- 上下文编码:找到相关的文档或段落后,模型将它们与原始输入(问题)一起编码。
- 生成:使用编码的上下文信息,模型生成输出(答案)。
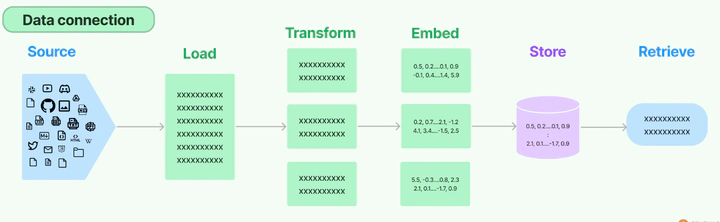
数据准备阶段
文档加载RAG 的第一步是文档加载。
下一个步骤是对文本进行转换. 文本分割器.
LangChain 提供的各种文本拆分器可以帮助你从下面几个角度设定你的分割策略和参数:
- 文本如何分割
- 块的大小
- 块之间重叠文本的长度
- 文本块形成之后,我们就通过 LLM 来做嵌入(Embeddings)
应用阶段
Retriever(检索器)
对比传统搜索引擎
传统搜索引擎和 RAG 技术在架构上确实有一些相似之处,都采用了两阶段的处理模式。
传统搜索引擎通常分为召回(Recall)和排序(Ranking)两个阶段:
- 召回阶段:通过倒排索引、term matching 等快速匹配文档,从海量库中筛选出与查询相关的候选文档集合。这一阶段侧重速度和覆盖度。
- 排序阶段:采用更精细的算法和更多特征,对召回的候选集进行精排,生成最终的排序结果。这一阶段侧重质量和相关性。
RAG 作为一种检索增强的生成式模型,也分为检索(Retrieval)和生成(Generation)两个阶段:
- 检索阶段:通过 embedding 向量相似度匹配等方式,从支撑知识库中检索出与输入最相关的 top-k 个知识片段。RAG 的检索通常是针对 passage 或 chunk 级别,相比传统搜索引擎粒度更细。
- 生成阶段:以输入 query 和检索出的知识片段为上下文,用生成式模型(如 seq2seq)产生最终的答案文本。生成阶段可以很好地整合和总结知识,生成连贯自然的答案。