向量数据库
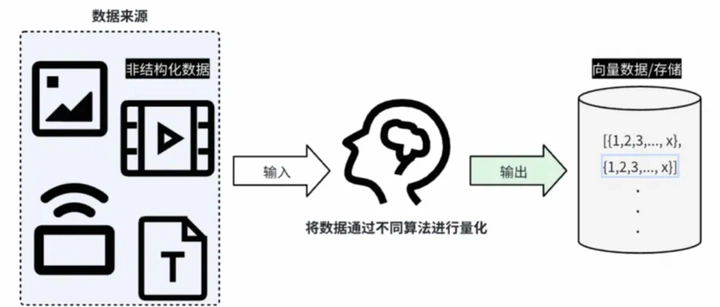
向量数据库是一种专为高效存储和检索高维向量数据而设计的数据库系统。
这些向量通常来源于机器学习和深度学习模型对非结构化数据(如文本、图像、音频、视频)的编码处理。通过将原始数据转化为密集的数值向量(生产使用一般向量维度会大于512),向量数据库能够支持诸如相似性搜索、推荐系统、图像检索、语音识别等多种应用场景。
基本概念
维度 (dimensionality)
该空间中的每个维度都可以被视为数据的一个特征或特征。 对于单词或句子,这些维度可以捕获句法角色、语义含义、上下文或各种抽象语言属性。 维度越多,表示就越细致,但也需要更多的计算资源。
向量 Embeddings
向量Embeddings是自然语言处理(NLP)中的一个基本概念,是单词、句子、文档、图像、音频或视频数据等对象的数字表示。
- 生成句子Embeddings的常用方法包括Doc2Vec (Document-to-vector)
- 卷积神经网络(cnn)和视觉几何组(VGG)用于生成图像Embeddings
下面这个示例把本地 05_embeddings/main.py 里的训练样本、相似文档检索和分类验证流程搬到了浏览器端。为了让页面可以直接运行,示例没有继续依赖 gensim.Doc2Vec,而是改成了一个 Pyodide + NumPy 的轻量 Embeddings 版本:
- 保留相同的训练样本、测试样本和查询文本
- 保留“文本向量化 -> 相似文档检索 -> 类别中心分类”的教学流程
- 使用确定性的 token 向量平均方式来构造文档 Embeddings,便于在浏览器里即时运行和修改
你可以直接编辑代码,然后点击运行:
点击“运行代码”查看 embeddings 检索与分类结果。
距离和相似度 (distance and similarity)
将单词或句子转换为向量的主要原因是为了测量相似度。 在这些向量空间中,任何两个向量之间的 “距离”(通常使用余弦相似度或欧几里德距离等度量)可以指示这两个项目的相似程度。 向量越接近,它们就越相似。
向量的相似性度量基于距离函数,常见的距离函数有欧式距离、余弦距离、点积距离,
- 欧式距离(L2 distance)衡量两个向量在空间中的直线距离。欧式距离存在尺度敏感性的局限性,通过归一化等技术可以有效降低尺度敏感性对相似度的干扰。欧式距离适用于低维向量,在高维空间下会逐渐失效。
- 余弦距离(Cosine similarity)衡量两个向量之间夹角的余弦值。余弦距离存在数值敏感性的局限性,因为其只考虑了向量的方向,而没有考虑向量的长度。余弦距离适用于高维向量或者稀疏向量。
- 点积距离(Dot product similarity)通过将两个向量的对应分量相乘后再全部求和而进行相似度衡量,点积距离同时考虑了向量的长度和方向。点积距离存在尺度敏感性和零向量的局限性。
常见向量数据库
依据是否开源与是否为专用向量数据库,将其分为四类。
第一类是开源的专用向量数据库,如 Chroma、Vespa、LanceDB、Marqo、Qdrant 和 Milvus,这些数据库专门设计用于处理向量数据。
- Milvus - 开源,由Zilliz开发,专为大规模向量相似性搜索设计,支持多种索引类型,适用于图像检索、推荐系统等场景。
- qdrant- 开源,是一款高性能的开源向量数据库,采用Rust开发,支持二进制量化技术。它提供多种索引策略和向量混合搜索功能,能够实现极高的性能(RPS>4000)和低延迟搜索。Qdrant特别适合性能敏感应用、高并发场景以及中小规模部署。
- FAISS (Facebook AI Similarity Search) - 开源库,由Facebook AI Research (FAIR)开发,针对相似性搜索进行了优化,特别是对于GPU加速的场景非常有效。当与 LangChain 结合使用时,它可以作为一个强大的本地向量存储方案,非常适合快速原型设计和中小型应用。
第二类是支持向量搜索的开源数据库,如 OpenSearch、PostgreSQL、ClickHouse 和 Cassandra,它们是常规数据库,但支持向量搜索功能。
- pgvector- 开源 pg 插件
第三类是商用的专用向量数据库,如 Weaviate 和 Pinecone,它们专门用于处理向量数据,但属于商业产品或通过商业许可获得源码。
第四类是支持向量搜索的商用数据库,如 Elasticsearch、Redis、Rockset 和 SingleStore,这些常规数据库支持向量搜索功能,同时属于商业产品或可通过商业许可获得源码。
- elasticsearch 8.0: https://www.elastic.co/search-labs/blog/vector-search-improvements
milvus
Milvus部署依赖许多外部组件,如存储元信息的ETCD、存储使用的MinIO、消息存储Pulasr 等等
qdrant
Qdrant完全独立开发,支持集群部署,不需要借助ETCD、Pulsar等组件
向量数据库技术原理
数据向量化:这是向量数据库工作的起点,涉及将非结构化数据(如文本、图像、音频)通过机器学习或深度学习模型转化为高维数值向量的过程。这个过程被称为嵌入(Embedding),目的是捕捉原始数据的语义特征。例如,文本可以通过词嵌入模型(如Word2Vec、BERT)转换为向量,图像则可能通过卷积神经网络(CNN)提取特征向量。
向量存储:将转换后的向量存储在数据库中。由于向量通常是高维的,存储方案需高效且可扩展,以支持海量数据。这通常涉及多维索引结构,以便快速定位和检索向量。
相似度计算:向量数据库的核心功能之一是快速计算向量间的相似度。常用的距离度量方法包括欧氏距离、余弦相似度等,这些度量方法帮助评估两个向量的接近程度,从而找到最相似的向量。
近似最近邻搜索(Approximate Nearest Neighbor, ANN):为了提高大规模数据集上的查询效率,向量数据库采用ANN算法。这些算法通过预先构建索引,牺牲极小的精确度换取大幅度的查询速度提升。常见的ANN索引方法包括基于树的方法(如KD树、Ball Tree)、基于哈希的方法(如LSH、PQ)、基于图的方法(如HNSW)、以及乘积量化方法等。
索引构建与更新:构建高效索引是向量数据库的基础,这一步骤通常在数据写入时完成。随着数据的增加和更新,索引也需要动态调整和优化,以维持查询性能。
分布式与并行处理:面对大规模数据集,向量数据库往往采用分布式架构,通过并行处理和数据分片技术来分散存储和计算压力,保证系统的扩展性和高性能。
索引
向量检索算法有 kNN(k-Nearest Neighbors)和 ANN ( Approximate Nearest Neighbor) 两种。
- kNN(k-Nearest Neighbors)是一种蛮力检索方式,当给定目标向量时,计算该向量与候选向量集中所有向量的相似度,并返回最相似的 K 条。当向量库中数据量很大时 kNN 会消耗很多计算资源,耗时也不理想
- ANN ( Approximate Nearest Neighbor)其基本思想是预先计算向量间的距离,并将距离相近的向量存储在一起,从而在检索时可以更高效。预先计算就是构建向量索引的过程
在向量数据库领域,HNSW(Hierarchical Navigable Small-World)和 DiskANN 正逐渐成为主流索引方案。
其中NHSW主要以内存搜索为主,DiskANN主要以磁盘搜索为主。
HNSW(Hierarchical Navigable Small-World 层次导航小世界图)

它是跳表和小世界图(SWG)结构的扩展,可以有效地找到近似的最近邻。
HNSW是一种基于多层图的算法,在顶层,我们可以看到一个由极少向量构成的图,这些向量之间的连线最长,也就是说,这是一个由相似度最低的相连向量构成的图。 我们越深入到较低层,发现的向量就越多,图也变得越密集,越来越多的向量彼此靠得更近。 在最底层,我们可以找到所有的向量,其中相似度最高的向量彼此距离最近。在搜索时,该算法从顶层的任意入口点开始,找到与查询向量最接近的向量(由灰色点表示)。 然后,它向下移动一层,并从上层离开的同一向量开始重复相同的过程,依此类推,逐层进行,直到到达最底层并找到查询向量的最近邻。
DiskANN (DISK Approximate Nearest Neighbors)
ANN计算每个候选点与查询点之间的实际距离(如欧几里得距离、余弦相似度)。然后根据与查询点的距离/相似度对候选项进行排名。排名靠前的候选人作为近似近邻返回。