vLLM
vLLM 是伯克利大学LMSYS组织开源的大语言模型高速推理框架.
vLLM 主要用于快速 LLM 推理和服务,通过一种名为PagedAttention的技术,动态地为请求分配KV cache显存,提升显存利用率。
基本概念
FLOPS:等同于FLOP/s,表示Floating Point Operations Per Second,即每秒执行的浮点数操作次数,用于衡量硬件计算性能。
FLOPs:表示Floating Point Operations,表示某个算法的总计算量(即总浮点运算次数),用于衡量一个算法的复杂度。
计算强度 (arithmetic intensity)
算法对于内存带宽的需求通常使用 计算强度 (arithmetic intensity) 来表示,单位是 OPs/byte。意思是在算法中平均每读入单位数据,能支持多少次运算操作。
算力 :也称为计算平台的性能上限,指的是一个计算平台倾尽全力每秒钟所能完成的浮点运算数。floating point operations per second.单位是 FLOPS or FLOP/s。
带宽 :也即计算平台的带宽上限,指的是一个计算平台倾尽全力每秒所能完成的内存交换量。单位是Byte/s。
计算强度上限 :两个指标相除即可得到计算平台的计算强度上限。它描述的是在这个计算平台上,单位内存交换最多用来进行多少次计算。单位是FLOPs/Byte
MAC(Memory Access Cost,存储访问开销)
MAC的开销主要来自两方面。一是从存储中读取数据;二是向存储中写数据。与CPU的情况类似,在GPU中,当需要计算时,需将数据从显存中读取并由计算单元进行计算操作。在计算完毕后,再写回到显存中。
大模型推理
一个常规的LLM推理过程通常分为两个阶段:预填充阶段( prefill ) 和 生成response的阶段( decode)。通常会使用KV cache技术加速推理。

为什么需要推理框架
除了分布式推理和支持量化之外,大模型推理框架最大的用处是加速推理。加速推理的主要目的是提高推理效率,减少计算和内存需求,满足实时性要求,降低部署成本:
常用的推理框架
vLLM 是一种基于PagedAttention的推理框架,通过分页处理注意力计算,实现了高效、快速和廉价的LLM服务。vLLM在推理过程中,将注意力计算分为多个页面,每个页面只计算一部分的注意力分布,从而减少了计算量和内存需求,提高了推理效率.
Ollama —— 零门槛、易用的本地推理平台.
SGLang —— 高吞吐量与极致响应的前沿引擎
Hugging Face TGI —— 生产级稳定推理服务平台
选择建议与未来展望
- 企业级高并发应用:对于在线客服、金融交易和智能文档处理等对延迟与吞吐量要求极高的场景,推荐选择 vLLM、TensorRT-LLM 或 Hugging Face TGI,它们在多 GPU 部署和低延迟响应方面表现尤为突出。
- 个人开发与本地原型:Ollama 凭借其跨平台、易上手的特性,非常适合个人原型验证和离线本地部署,而 Llama.cpp 则满足了无 GPU 环境下的基本推理需求。
- 国产硬件部署:LMDeploy 针对国产 GPU 进行了深度优化,具备多模态处理优势,适合国内企业和政府机构在特定硬件环境下部署。
- 新兴技术探索:SGLang 与 MLC-LLM 分别在高吞吐量和编译优化上展示了前沿技术潜力,虽然当前还存在一定局限,但未来发展前景值得期待
序列建模的演进之路
从 计算机视觉(Computer Vision,CV)为起源发展起来的神经网络,其核心架构有三种:
FNN(Feedforward Neural Network 前馈神经网络 ) : 数据从输入层单向流动到输出层,无循环结构,各层之间通过全连接或特定方式传递信息
CNN(Convolutional Neural Network 卷积神经网络): 训练参数量远小于全连接神经网络的卷积层来进行特征提取和学习
RNN( Recurrent Neural Networks 循环神经网络 ):序列处理的开拓者,能够使用历史信息作为输入、包含环和自重复的网络
局限性:然而,由于梯度消失问题,普通RNN很难学习长距离依赖。随着序列长度增加,早期输入的信息会迅速衰减或爆炸。
自注意力(Self-Attention)机制: 长依赖问题的解决方案
也称为内部注意力(Intra-Attention).
注意力机制(attention mechanism)最早是在序列到序列模型中提出的,用于解决机器翻译任务。
自注意力模型采用查询-键-值(Query-Key-Value,QKV)模式.
在 Transformer 的 Encoder 结构中,使用的是 注意力机制的变种 —— 自注意力(self-attention,自注意力)机制。
为什么 Self-Attention 解决了长依赖问题?
并行计算:不像RNN需要顺序处理,Self-Attention可以并行计算所有位置 路径长度恒定:任意两个位置之间的信息传递只需一步操作 加权求和:通过自适应权重聚合所有位置的信息
FlashAttention(Fast and Memory Efficient Exact Attention with IO-Awareness))
(1)Fast(with IO-Awareness),计算快。计算慢的卡点不在运算能力,而是在读写速度上。所以它通过降低对显存(HBM)的访问次数来加快整体运算速度,这种方法又被称为O-Awareness。
(2)Memory Efficient,节省显存。
(3)Exact Attention,精准注意力。
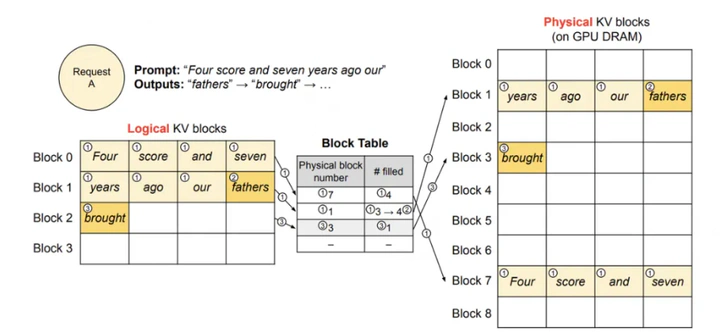
PagedAttention
PagedAttention 的设计灵感来自操作系统的虚拟内存分页管理技术。
场景
PagedAttention在Parallel Sampling和Beam Search 场景上的优势
Parallel Sampling

Parallel Sampling:我给模型发送一个请求,希望它对prompt做续写,并给出三种不同的回答。我们管这个场景叫parallel sampling.
Beam Search
Beam Search:束搜索,这是LLM常用的decode策略之一,即在每个decode阶段,我不是只产生1个token,而是产生top k个token(这里k也被称为束宽)。top k个token必然对应着此刻的top k个序列。 我把这top k个序列喂给模型,假设词表的大小为|V|,那么在下一时刻,我就要在k*|V|个候选者中再选出top k.
