Calico
基本知识
tcpdump
$ tcpdump -nn udp port 53 or host 35.190.27.188
-nn ,表示不解析抓包中的域名(即不反向解析)、协议以及端口号。
udp : 协议过滤,只显示 UDP协议
port 53 : 端口过滤额, 端口号(包括源端口和目的端口)为53的包。
host 35.190.27.188: 主机过滤, 表示只显示 IP 地址(包括源地址和目的地址)为35.190.27.188的包。
or: 逻辑表达式, 这两个过滤条件中间的 “or”,表示或的关系,也就是说,只要满足上面两个条件中的任一个,就可以展示出来。
net 192.168.0.0 网络地址过滤
输出格式
时间戳 协议 源地址.源端口 > 目的地址.目的端口 网络包详细信息
保存到 ping.pcap 文件
$ tcpdump -nn udp port 53 or host 35.190.27.188 -w ping.pcap
BGP (外网路由协议(Border Gateway Protocol)
求最短路径常用的有两种方法,一种是Bellman-Ford算法,一种是Dijkstra算法。
动态路由算法
- 第一大类的算法称为距离矢量路由(distance vector routing)。它是基于Bellman-Ford算法的
- 第二大类算法是链路状态路由(link state routing),基于Dijkstra算法。
BGP又分为两类,eBGP(External Border Gateway Protocol )和iBGP (Internal Border Gateway Protocol)。
iGGP: 负责在同一AS内的BGP路由器间传播路由,通过递归方式进行路径选择. eBGP: 用于在不同AS间传播BGP路由,它基于hop-by-hop 机制进行路由选择.
BGP协议使用的算法是路径矢量路由协议(path-vector protocol)。它是距离矢量路由协议的升级版。
自治系统(Autonomous System, AS) 是指一组相互信任、使用相同路由策略的网络或子网,通过BGP(边界网关协议)进行通信。
自治系统编号(Autonomous System Number,ASN) 是一个唯一标识自治系统的32位整数,用于在BGP(边界网关协议)中标识不同的网络或网络提供商。
root@node1:/etc/cni/net.d# calicoctl get nodes --output=wide
NAME ASN IPV4 IPV6
node1 (64512) 172.16.7.30/16
node2 (64512) 172.16.7.31/16
node3 (64512) 172.16.7.32/16
node4 (64512) 172.16.7.33/16
node5 (64512) 172.16.7.34/16
路由聚合(Route Aggregation)
路由聚合,也称为路由汇总或路由压缩,是一种网络设计技术,它允许将多个具有相同下一跳地址的路由条目合并成一个单一的路由。 这个过程基于子网划分的原理,通过使用更长的子网掩码来表示更大的地址范围。
路由聚合的优势
路由聚合的主要优势在于它能够显著减少路由表的大小,这对于大型网络尤其重要。较小的路由表意味着:
- 更快的查找速度:路由器查找路由的时间更短,从而提高了数据包转发的速度。
- 更容易的管理:网络管理员需要配置和维护的路由条目更少,减轻了管理工作的负担。
- 更好的可扩展性:网络可以通过添加新的子网来轻松扩展,而无需对每个新子网都添加单独的路由条目
路由聚合的工作原理
路由聚合的关键在于找到一个包含所有子网的最小子网,这个子网的子网掩码可以覆盖所有子网的地址范围。这个过程通常涉及到以下步骤:
- 识别子网:确定需要聚合的子网列表。
- 计算最小子网:找到能够包含这些子网的最小子网地址和子网掩码。
- 配置聚合路由:在路由器上配置一个指向这个最小子网的聚合路由,其下一跳地址与子网的下一跳地址相同。
- 更新路由表:将所有单独的子网路由替换为这个聚合路由
Proxy ARP
能就是使那些在同一网段却不在同一物理网络上的计算机或路由器能够相互通信。
# 查看 ens32 是否开启
root@node1:~# cat /proc/sys/net/ipv4/conf/ens32/proxy_arp
0
root@node1:~# cat /proc/sys/net/ipv4/conf/calid7b92ca9b15/proxy_arp
1
XDP( eXpress Data Path)
XDP(eXpress Data Path)提供了一个内核态、高性能、可编程 BPF 包处理框架。 本质上是Linux Kernel中的一个eBPF Hook(钩子),可以动态挂载,使得ebpf程序能够在数据报文到达网络驱动层时提前进行针对性的高速处理。 XDP可以与内核协同工作,既可以绕过繁琐的TCP/IP协议栈,也可以复用TCP/IP协议栈以及内核基础设施。
XDP 在内核收包函数 receive_skb() 之前
在 receive_skb() 之后

XDP的三种工作模式
- Native XDP 原生模式(性能高,需要网卡支持),即运行在网卡驱动实现的的 poll() 函数中,需要网卡驱动的支持;
- Generic XDP(性能良好,Linux内核支持最好),即上面提到的如果网卡驱动不支持XDP,则可以运行在 receive_skb() 函数中;
- Offloaded XDP 卸载模式(性能最高,支持的网卡最少),这种模式是指将XDP程序offload到网卡中,这需要网卡硬件的支持,JIT编译器将BPF代码翻译成网卡原生指令并在网卡上运行
XDP专为高性能而设计,相较与DPDK来说,具有以下优点:
- 无需专门硬件,无需大页内存,无需独占CPU等资源,任何有Linux驱动的网卡都可以支持,无需引入第三方代码库。
- 兼容内核协议栈,可选择性复用内核已有的功能。
- 保持了内核的安全边界,提供与内核API一样稳定的接口。
- 无需对网络配置或管理工具做任何修改。
- 服务不中断的前提下动态重新编程,这意味着可以按需加入或移除功能,而不会引起任何流量中断,也能动态响应系统其他部分的的变化。
- 主流的发行版中,Linux内核已经内置并启用了XDP,并且支持主流的高速网络驱动,4.8+的内核已内置,5.4+能够完全使用。
缺点:
- XDP不提供缓存队列(qdisc),TX设备太慢时会直接丢包,因而不能在接收队列(RX RING)比发送队列(TX RING)快的设备上使用XDP。
- 由于不具备缓存队列,对与IP分片不太友好。
- XDP程序是专用的,不具备网络协议栈的通用性。
XDP 系统由四个主要部分组成:
XDP device driver hook:网卡收到包之后直接运行;
eBPF虚拟机:执行 XDP 程序(以及内核其他模块加载的 BPF 程序);
BPF maps:使不同 BPF 程序之间、BPF 程序与用户空间应用之间能够通信;
eBPF verifier:确保程序不包含任何可能会破坏内核的操作。
应用场景 AF_XDP
AF_XDP是XDP技术的一种应用场景,AF_XDP是一种高性能Linux socket
Calico组网模式
IPIP 模式(不同网段)
Calico默认网络架构,IPIP 可理解为IPinIP,属于overlay的网络架构。不依赖于外部交换机设备,即可实现网络组网。 缺点是报文的封装和解封装对网络效率有影响,节点规模有限制。

# 尽管这条规则的下一跳地址仍然是Node B 的IP地址,但这一次,要负责将IP包发出去的设备,变成了tunl0。
10.5.2.0/16 via 10.120.179.8 tunl0

经过封装后的新的IP包的目的地址,正是原IP包的下一跳地址,即Node B的IP地址:10.120.179.8。
在实际测试中,Calico IPIP模式与Flannel VXLAN模式的性能大致相当。
VXLAN (不同网段)
BGP 模式 (相同网段)
两种模式
- 全互联模式(node-to-node mesh)
全互联模式 每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N^2,如果数量过大会消耗大量连接。如果集群数量超过100台官方不建议使用此种模式。
(⎈|kubeasz-test:metallb)➜ git_download kubectl get bgpconfigurations.crd.projectcalico.org default -o yaml
apiVersion: crd.projectcalico.org/v1
kind: BGPConfiguration
metadata:
name: default
spec:
asNumber: 64512
listenPort: 179
logSeverityScreen: Info
nodeToNodeMeshEnabled: true
- 路由反射模式Router Reflection(RR)
RR模式 中会指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。 在calico中可以通过Global Peer实现RR模式。
Calico 项目提供的 BGP 网络解决方案,与 Flannel 的 host-gw 模式几乎一样。也就是说,Calico也是基于路由表实现容器数据包转发,但不同于Flannel使用flanneld进程来维护路由信息的做法,而Calico项目使用BGP协议来自动维护整个集群的路由信息
不适合 BGP 模式
- 节点跨网段
- 阻止 BGP 报文的网路环境
- 对入站数据包进行强制源地址和目的地址校验
IPAM 地址管理
calico 使用 calico-ipam 插件,可以划分 podcird 到多个pool.
(⎈|kubeasz-test:metallb)➜ ~ kubectl get cm -n kube-system calico-config -o yaml
apiVersion: v1
data:
calico_backend: vxlan
cluster_type: kubespray
cni_network_config: |-
{
"name": "k8s-pod-network",
"cniVersion":"0.3.1",
"plugins":[
{
"datastore_type": "kubernetes",
"nodename": "__KUBERNETES_NODE_NAME__",
"type": "calico",
"log_level": "info",
"log_file_path": "/var/log/calico/cni/cni.log",
"ipam": {
"type": "calico-ipam",
"assign_ipv4": "true"
},
"policy": {
"type": "k8s"
},
"kubernetes": {
"kubeconfig": "__KUBECONFIG_FILEPATH__"
}
},
{
"type":"portmap",
"capabilities": {
"portMappings": true
}
},
{
"type":"bandwidth",
"capabilities": {
"bandwidth": true
}
}
]
}
kind: ConfigMap
metadata:
annotations:
kubectl.kubernetes.io/last-applied-configuration: |
{"apiVersion":"v1","data":{"calico_backend":"vxlan","cluster_type":"kubespray","cni_network_config":"{\n \"name\": \"k8s-pod-network\",\n \"cniVersion\":\"0.3.1\",\n \"plugins\":[\n {\n \"datastore_type\": \"kubernetes\",\n \"nodename\": \"__KUBERNETES_NODE_NAME__\",\n \"type\": \"calico\",\n \"log_level\": \"info\",\n \"log_file_path\": \"/var/log/calico/cni/cni.log\",\n \"ipam\": {\n \"type\": \"calico-ipam\",\n \"assign_ipv4\": \"true\"\n },\n \"policy\": {\n \"type\": \"k8s\"\n },\n \"kubernetes\": {\n \"kubeconfig\": \"__KUBECONFIG_FILEPATH__\"\n }\n },\n {\n \"type\":\"portmap\",\n \"capabilities\": {\n \"portMappings\": true\n }\n },\n {\n \"type\":\"bandwidth\",\n \"capabilities\": {\n \"bandwidth\": true\n }\n }\n ]\n}"},"kind":"ConfigMap","metadata":{"annotations":{},"name":"calico-config","namespace":"kube-system"}}
creationTimestamp: "2025-06-23T05:13:15Z"
name: calico-config
namespace: kube-system
resourceVersion: "1602"
uid: 5ddb6570-a0a3-4566-81a7-2457186da8fd
确保 ipam 使用 calico-ipam
Calico通过IPPool进行IPAM管理,IPPool定义了地址池名字、地址段、blockSize等字段。
# 查看默认 ipPool
(⎈|kubeasz-test:metallb)➜ ~ kubectl get ippools.crd.projectcalico.org default-pool -o yaml
apiVersion: crd.projectcalico.org/v1
kind: IPPool
metadata:
annotations:
projectcalico.org/metadata: '{"creationTimestamp":"2025-06-23T05:13:00Z"}'
creationTimestamp: "2025-06-23T05:13:00Z"
generation: 1
name: default-pool
resourceVersion: "1560"
uid: 94fcf297-08e1-48e6-8508-81430ca903c4
spec:
allowedUses:
- Workload
- Tunnel
blockSize: 26
cidr: 10.233.64.0/18 # 填写创建集群时规划的cidr地址段
ipipMode: Never # Never不使用IPIP模式,Always时代表使用IPIP模式,CrossSubnet代表混合模式,跨网段则ipip,不跨网段BGP
natOutgoing: true #nat转发
nodeSelector: all() # all() 选择所有节点
vxlanMode: Always # vxlanMode 可以为Always,CrossSubnet,
root@node1:/opt/calico# calicoctl ipam show
+----------+----------------+-----------+------------+--------------+
| GROUPING | CIDR | IPS TOTAL | IPS IN USE | IPS FREE |
+----------+----------------+-----------+------------+--------------+
| IP Pool | 10.233.64.0/18 | 16384 | 61 (0%) | 16323 (100%) |
+----------+----------------+-----------+------------+--------------+
字段解释:
- block/blockSize: block主要功能是路由聚合,减少对外宣告路由条目。 block在POD所在节点自动创建,如在worker01节点创建1.1.1.1的POD时,blocksize为29,则该节点自动创建1.1.1.0/29的block,对外宣告1.1.1.0/29的BGP路由,并且节点下发1.1.1.0/29的黑洞路由和1.1.1.1/32的明细路由。 在IBGP模式下,黑洞路由可避免环路。 如果blockSize设置为32,则不下发黑洞路由也不会造成环路,缺点是路由没有聚合,路由表项会比较多,需要考虑交换机路由器的容量。
Calico创建block时,会出现借用IP的情况。 如在 worker01节点存在1.1.1.0/29的block,由于worker01节点负载很高,地址为1.1.1.2的POD被调度到worker02节点,这种现象为IP借用。 woker02节点会对外宣告1.1.1.2/32的明细路由,在IBGP模式下,交换机需要开启RR模式,将路由反射给worker01上,否则在不同worker节点的同一个block的POD,由于黑洞路由的存在,导致POD之间网络不通。 可通过ipamconfigs来管理是否允许借用IP(strictAffinity)、每个节点上最多允许创建block的数量(maxBlocksPerHost)等。
- nodeselector: 可以根据拓扑分配不同段的IP地址
# 创建了两个 IP 池,它只为标签为zone=west和zone=west2的节点分配 IP 地址
kind: IPPool
metadata:
name: zone-west-ippool1
spec:
cidr: 172.122.1.0/24
ipipMode: Always
natOutgoing: true
nodeSelector: zone == "west"
---
apiVersion: projectcalico.org/v3
kind: IPPool
metadata:
name: zone-west-ippool2
spec:
cidr: 172.122.2.0/24
ipipMode: Always
natOutgoing: true
nodeSelector: zone == "west2"
- ipipMode
- ipip always模式(纯ipip模式)
- ipip cross-subnet模式(ipip-bgp混合模式),指同子网内路由采用bgp,跨子网路由采用ipip
组件
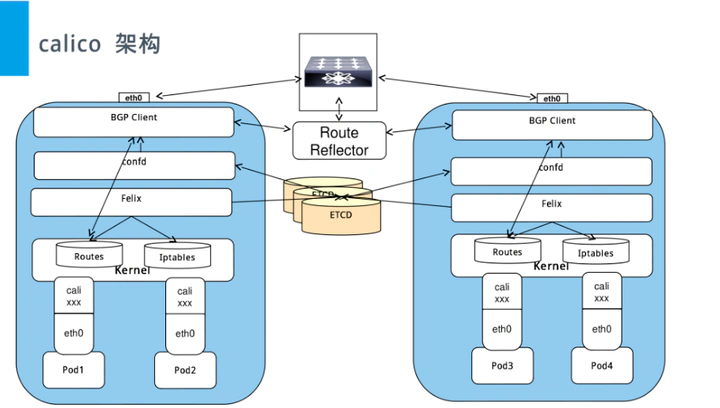
架构图: https://docs.tigera.io/calico/3.29/reference/architecture/overview
- Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。
- etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
- BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通。
- calico-controller: 实现网络策略功能,支持 calico 相关的 CRD 资源.
- BGP Route Reflector(RR 路由反射):在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
- typha: 各个 calico-node 同 calico datastore 通讯的中间层,减轻大规模集群 calico datastore 的负载,具有缓存功能. 50 节点以上,建议使用.
- Whisker: v3.30 图形工具.
calico 数据面
传统标准数据面

- 驱动在内存中分配一片缓冲区用来接收数据包,叫做 sk_buffer;
- 将上述缓冲区的地址和大小(即接收描述符),加入到 rx ring buffer。描述符中的缓冲区地址是 DMA 使用的物理地址;
- 驱动通知网卡有一个新的描述符;
- 网卡从 rx ring buffer 中取出描述符,从而获知缓冲区的地址和大小;
- 网卡收到新的数据包;
- 网卡将新数据包通过 DMA 直接写到 sk_buffer 中。

- 网卡收到一个包(通过 DMA 放到 ring-buffer)。然后通过硬中断,告诉中断处理程序已经收到了网络包。
- 包经过 XDP hook 点。
- 内核给包分配内存创建(sk_buff)(包的内核结构体表示),然后再通过软中断,通知内核收到了新的网络帧.
- 包经过 GRO(Generic Receive Offload) 处理,对分片包进行重组。
- 包进入 tc(traffic conrtrol)的 ingress hook。接下来,所有橙色的框都是 Netfilter 处理点。
- Netfilter:在 PREROUTING hook 点处理 raw table 里的 iptables 规则。
- 包经过内核的连接跟踪(conntrack)模块。
- Netfilter:在 PREROUTING hook 点处理 mangle table 的 iptables 规则。
- Netfilter:在 PREROUTING hook 点处理 nat table 的 iptables 规则。
- 进行路由判断(FIB:Forwarding Information Base,路由条目的内核表示) 。接下来又是四个 Netfilter 处理点。
- Netfilter:在 FORWARD hook 点处理 mangle table 里的 iptables 规则。
- Netfilter:在 FORWARD hook 点处理 filter table 里的 iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 mangle table 里的 iptables 规则。
- Netfilter:在 POSTROUTING hook 点处理 nat table 里的 iptables 规则。
- 包到达 TC egress hook 点,会进行出方向(egress)的判断,例如判断这个包是到本 地设备,还是到主机外。
- 对大包进行分片。根据 step 15 判断的结果,这个包接下来可能会:
- 发送到一个本机 veth 设备,或者一个本机 service endpoint,
- 或者,如果目的 IP 是主机外,就通过网卡发出去
eBPF

对比可以看出,Calico eBPF datapath 做了短路处理:从 tc ingress 直接到 tc egress,节省了 9 个中间步骤(总共 17 个)。 更重要的是:这个 datapath 绕过了 整个 Netfilter 框架(橘黄色的框们),Netfilter 在大流量情况下性能是很差的。
# 检查 BPF 文件系统
root@node1:~# mount | grep "/sys/fs/bpf"
bpf on /sys/fs/bpf type bpf (rw,nosuid,nodev,noexec,relatime,mode=700)
Calico 的 eBPF 数据平面是标准 Linux 数据平面(基于 iptables)的替代方案。 标准数据平面侧重于通过与 kube-proxy 和 iptables 规则进行交互来实现兼容性,而 eBPF 数据平面则侧重于性能、延迟和改善用户体验,并提供标准数据平面中无法实现的功能。 作为其中的一部分,eBPF 数据平面将 kube-proxy 替换为 eBPF 实现。主要的“用户体验”功能是在流量到达 NodePort 时保留来自集群外部的流量源 IP;这使服务器端日志和网络策略在该路径上更加有用。
新的数据平面与 Calico 的标准Linux网络数据平面相比
它可以扩展到更高的吞吐量。
它每 GBit 使用更少的 CPU。
它原生支持 Kubernetes 服务(不需要 kube-proxy):
- 减少数据包到服务的第一个数据包延迟。
- 将外部客户端源 IP 地址一直保留到 pod。
- 支持 DSR(Direct Server Return),实现更高效的服务路由。
- 使用比 kube-proxy 更少的 CPU 来保持数据平面同步。