Cilium
容器的网络发展路线
基于 Linux bridge 以及基于 ovs 实现的 overlay 的网络。
基于 bgp/hostgw 等基于路由能力的网络。
基于 macvlan,ipvlan 等偏物理网络的 underlay 的网络。
基于 Kernel 的 eBPF 的技术实现的网络。
基于 dpdk/sriov/vpp/virtio-user/offload/af-xdp 实现的用户态的网络
bpf 相关知识
BPF( Berkeley Packet Filter). 包括了 cBPF(classic Berkeley Packet Filter) 和 eBPF(extended Berkeley Packet Filter)。
bpftool
BPFTOOL 是linux内核自带的用于对eBPF程序和eBPF map进行检查与操作的工具软件。
bpftool的常用功能
sudo bpftool prog list: 显示所有已经被load到系统里的eBPF程序的信息列表,除了显示功能外,还支持dump等功能,可以通过man bpftool prog来查看具体支持的功能。
bpftool net list 显示内核网络子系统里的eBPF程序,除了显示功能外,还支持其它功能,可以通过man bpftool net来查看具体支持的功能。
bpftool link list 显示所有激活的链接,除了显示功能外,还支持其它功能,可以通过man bpftool link来查看具体支持的功能。
bpftool perf list 显示系统里所有raw_tracepoint, tracepoint, kprobe attachments ,除了显示功能外,还支持其它功能,可以通过man bpftool perf来查看具体支持的功能。
bpftool btf list 显示所有BPF Type Format (BTF)数据 ,除了显示功能外,还支持其它功能,可以通过man bpftool btf来查看具体支持的功能。
bpftool map list 显示系统内已经载入的所有bpf map数据,除了显示功能外,还支持其它功能,可以通过man bpftool map来查看具体支持的功能。
bpftool feature probe dev eth0: 查看eth0支持的eBPF特性
root@node5:~# bpftool feature probe | grep map_type
eBPF map_type hash is available
eBPF map_type array is available
eBPF map_type prog_array is available
eBPF map_type perf_event_array is available
eBPF map_type percpu_hash is available
eBPF map_type percpu_array is available
eBPF map_type stack_trace is available
eBPF map_type cgroup_array is available
eBPF map_type lru_hash is available
eBPF map_type lru_percpu_hash is available
eBPF map_type lpm_trie is available
eBPF map_type array_of_maps is available
eBPF map_type hash_of_maps is available
eBPF map_type devmap is available
eBPF map_type sockmap is available
eBPF map_type cpumap is available
eBPF map_type xskmap is available
eBPF map_type sockhash is available
eBPF map_type cgroup_storage is available
eBPF map_type reuseport_sockarray is available
eBPF map_type percpu_cgroup_storage is available
eBPF map_type queue is available
eBPF map_type stack is available
eBPF map_type sk_storage is available
eBPF map_type devmap_hash is available
eBPF map_type struct_ops is available
eBPF map_type ringbuf is available
eBPF map_type inode_storage is available
eBPF map_type task_storage is available
eBPF map_type bloom_filter is available
eBPF map_type user_ringbuf is available
eBPF map_type cgrp_storage is available
BTF(BPF Type Format)
BTF(BPF Type Format)是内嵌在BPF(Berkeley Packet Filter)程序中的数据结构描述信息.
BTF是为了实现更复杂的eBPF程序而设计的。其提供了一种机制,通过它可以将编程时使用的数据结构(如C语言中的结构体、联合体、枚举等)的信息嵌入到eBPF程序中。这样做的主要目的是为了让eBPF程序在运行时能够具有类型安全(Type Safety),同时也便于内核和用户空间的程序理解和操作这些数据结构。 在eBPF程序开发过程中,用户通常会在用户空间编写C代码,然后使用特定的编译器(如clang)编译这些代码为eBPF字节码。 由于C程序中定义的复杂数据结构信息在编译为eBPF字节码过程中会丢失,因此BTF被设计来保留这些信息。 当eBPF程序加载到内核时,BTF信息可以被内核使用,以确保程序操作的数据结构与内核预期的一致,从而保证程序的正确运行。
BTF 规范包含两个部分:
- BTF 内核 API
- BTF ELF 文件格式
内核 API 是用户空间和内核之间的约定。内核在使用之前使用 BTF 信息对其进行验证。ELF 文件格式是一个用户空间 ELF 文件和 libbpf 加载器之间的约定。
cBPF(classic BPF)
cBPF 的工作原理很简单,编写一段 BPF 指令,用来判断给定的网络数据包是否符合过滤条件:如果符合过滤条件,则接收或不接收该数据包。 换句话说,就是给 BPF 指令输入一个网络数据包,该段指令返回 0(表示拒绝数据包) 或 非 0 值(表示接收数据包)。当然,过滤指令是 BPF 虚拟机类型的,所以还要有一个 BPF 指令解释器,将 BPF 指令翻译成本地指令(如 ARM,x86)来执行。
eBPF(extended BPF)
eBPF 是嵌入在 Linux 内核中的虚拟机。它允许将小程序加载到内核中,并附加到钩子上,当某些事件发生时会触发这些钩子。这允许(有时大量)定制内核的行为。

eBPF 的执行需要三步:
从用户跟踪程序生成 BPF 字节码;
加载到内核中运行;
向用户空间输出结果。
eBPF 核心概念:指令集、映射、辅助函数、尾调用
- 指令集 (Instruction Set):eBPF 拥有一套通用的精简指令集(RISC),最初设计用于以 C 语言的子集编写程序,并通过编译器后端(如 LLVM)编译成 eBPF 指令。BPF 程序拥有 11 个 64 位寄存器(r0-r10)、一个程序计数器和一个 512 字节的栈空间。

映射 (Maps):eBPF 映射是驻留在内核空间的高效键值存储,是 eBPF 程序存储和共享状态的关键机制。
辅助函数 (Helper Functions):辅助函数是内核提供的一组预定义函数,eBPF 程序可以通过调用这些函数来与内核其他子系统交互或执行特定操作,例如操作映射(查找、更新、删除元素)、修改数据包内容、获取当前时间戳、进行尾调用等。

- 尾调用 (Tail Calls):尾调用是一种机制,允许一个 eBPF 程序调用另一个 eBPF 程序,而无需返回到原始程序。
eBPF 应用
- bcc(https://github.com/iovisor/bcc): 提供一套开发工具和脚本。
eBPF 的实现原理

1、BPF Verifier(验证器)
确保 eBPF 程序的安全。验证器会将待执行的指令创建为一个有向无环图(DAG),确保程序中不包含不可达指令
2、BPF JIT
将 eBPF 字节码编译成本地机器指令,以便更高效地在内核中执行
3、多个 64 位寄存器、一个程序计数器和一个 512 字节的栈组成的存储模块
用于控制eBPF程序的运行,保存栈数据,入参与出参
4、BPF Helpers(辅助函数)
提供了一系列用于 eBPF 程序与内核其他模块进行交互的函数。这些函数并不是任意一个 eBPF 程序都可以调用的,具体可用的函数集由 BPF 程序类型决定。
5、BPF Map & context
用于提供大块的存储,这些存储可被用户空间程序用来进行访问,进而控制 eBPF 程序的运行状态。
eBPF 程序分类和使用场景
eBPF 程序类型决定了一个 eBPF 程序可以挂载的事件类型和事件参数,这也就意味着,内核中不同事件会触发不同类型的 eBPF 程序。
根据内核头文件 include/uapi/linux/bpf.h 中 bpf_prog_type 的定义,Linux 内核 v5.13 已经支持 30 种不同类型的 eBPF 程序(
# 查询当前系统支持的程序类型
root@node5:~# bpftool feature probe | grep program_type
eBPF program_type socket_filter is available
eBPF program_type kprobe is available
eBPF program_type sched_cls is available
eBPF program_type sched_act is available
eBPF program_type tracepoint is available
eBPF program_type xdp is available
eBPF program_type perf_event is available
eBPF program_type cgroup_skb is available
eBPF program_type cgroup_sock is available
eBPF program_type lwt_in is available
eBPF program_type lwt_out is available
eBPF program_type lwt_xmit is available
eBPF program_type sock_ops is available
eBPF program_type sk_skb is available
eBPF program_type cgroup_device is available
eBPF program_type sk_msg is available
eBPF program_type raw_tracepoint is available
eBPF program_type cgroup_sock_addr is available
eBPF program_type lwt_seg6local is available
eBPF program_type lirc_mode2 is NOT available
eBPF program_type sk_reuseport is available
eBPF program_type flow_dissector is available
eBPF program_type cgroup_sysctl is available
eBPF program_type raw_tracepoint_writable is available
eBPF program_type cgroup_sockopt is available
eBPF program_type tracing is available
eBPF program_type struct_ops is available
eBPF program_type ext is available
eBPF program_type lsm is available
eBPF program_type sk_lookup is available
eBPF program_type syscall is available
eBPF program_type netfilter is available
主要是分为3大使用场景:
- 跟踪
tracepoint, kprobe, perf_event等,主要用于从系统中提取跟踪信息,进而为监控、排错、性能优化等提供数据支撑。
- 网络
xdp, sock_ops, cgroup_sock_addr , sk_msg等,主要用于对网络数据包进行过滤和处理,进而实现网络的观测、过滤、流量控制以及性能优化等各种丰富的功能,这里可以丢包,重定向。
根据事件触发位置的不同,网络类 eBPF 程序又可以分为 XDP(eXpress Data Path,高速数据路径)程序、TC(Traffic Control,流量控制)程序、套接字程序以及 cgroup 程序,
- 安全和其他
lsm,用于安全.
kprobe
kprobe 允许在内核函数的入口处插入一个断点。 当 CPU 执行到这个位置时,会触发一个陷入(trap),CPU 切换到你预先定义的处理函数(probe handler)执行。 这个处理函数可以访问和修改内核的状态,包括 CPU 寄存器、内核栈、全局变量等。执行完处理函数后,CPU 会返回到断点处,继续执行原来的内核代码.
kretprobe 允许在内核函数返回时插入探测点。这对于追踪函数的返回值或者函数的执行时间非常有用。 kretprobe 的工作原理是在函数的返回地址前插入一个断点。当函数返回时,CPU 会先跳转到你的处理函数,然后再返回到原来的地址。
也不是所有的函数都是支持kprobe机制,可以通过cat /sys/kernel/debug/tracing/available_filter_functions查看当前系统支持的函数
tracepoint
tracepoints 是 Linux 内核中的一种机制,它们是在内核源代码中预定义的钩子点,用于插入用于跟踪和调试的代码
tracepoints 是在内核源代码中预定义的,提供了稳定的 ABI。即使内核版本升级,tracepoint 的名称和参数也不会改变,这使得开发者可以编写依赖于特定 tracepoint 的代码,而不用担心在未来的内核版本中这些 tracepoint 会改变。
tracepoints 对性能的影响非常小。只有当 tracepoint 被激活,并且有一个或多个回调函数(也称为探针)附加到它时,它才会消耗 CPU 时间。这使得 tracepoints 非常适合在生产环境中使用
socket
socket 就是和网络包相关的事件,常见的网络包处理函数有sock_filter和sockops。
其中和socket相关的事件有:
- BPF_PROG_TYPE_SOCKET_FILTER: 这种类型的 eBPF 程序设计用于处理网络数据包
- BPF_PROG_TYPE_SOCK_OPS 和 BPF_PROG_TYPE_SK_SKB: 这两种类型的 eBPF 程序设计用于处理 socket 操作和 socket 缓冲区中的数据包
- BPF_PROG_TYPE_SK_MSG:用于处理 socket 消息
tc (traffic control 流量控制)
Linux 流量控制通过网卡队列、排队规则、分类器、过滤器以及执行器等,实现了对网络流量的整形调度和带宽控制。
子系统包括 qdisc(queueing discipline 队列规则)、class、classifier(filter)、action等概念,eBPF程序可以作为classifier被挂载
TC 模块实现流量控制功能使用的排队规则分为两类:无分类排队规则、分类排队规则。无分类排队规则相对简单,而分类排队规则则引出了分类和过滤器等概念,使其流量控制功能增强
xdp(eXpress Data Path)
XDP机制的主要目标是在接收数据包时尽早处理它们,以提高网络性能和降低延迟。它通过将eBPF程序附加到网络设备的接收路径上来实现这一目标。
uprobe(User Probe)
利用了Linux内核中的ftrace(function trace)框架来实现。通过uprobe,可以在用户空间程序的指定函数入口或出口处插入探测点,当该函数被调用或返回时,可以触发事先定义的处理逻辑。
动态追踪的事件源
动态追踪所使用的事件源,可以分为静态探针、动态探针以及硬件事件等三类

- 硬件事件通常由性能监控计数器 PMC(Performance Monitoring Counter)产生,包括了各种硬件的性能情况,比如 CPU 的缓存、指令周期、分支预测等等。
- 静态探针,是指事先在代码中定义好,并编译到应用程序或者内核中的探针。这些探针只有在开启探测功能时,才会被执行到;未开启时并不会执行。常见的静态探针包括内核中的跟踪点(tracepoints)和 USDT(Userland Statically Defined Tracing)探针。
- 动态探针,则是指没有事先在代码中定义,但却可以在运行时动态添加的探针,比如函数的调用和返回等。动态探针支持按需在内核或者应用程序中添加探测点,具有更高的灵活性。常见的动态探针有两种,即用于内核态的 kprobes 和用于用户态的 uprobes。
tc(Traffic Control)命令
Linux操作系统中的流量控制器TC(Traffic Control)用于Linux内核的流量控制,主要是通过在输出端口处建立一个队列来实现流量控制。
流量控制方式
流量控制包括以下几种方式:
- SHAPING(限制): 当流量被限制,它的传输速率就被控制在某个值以下。限制值可以大大小于有效带宽,这样可以平滑突发数据流量,使网络更为稳定。shaping(限制)只适用于向外的流量。
- SCHEDULING(调度): 通过调度数据包的传输,可以在带宽范围内,按优先级分配带宽。SCHEDULING(调度)也只适于向外的流量。
- POLICING(策略): SHAPING用于处理向外的流量,而 POLICING(策略)用于处理接收到的数据。
- DROPPING(丢弃): 如果流量超过某个设定的带宽,就丢弃数据包,不管是向内还是向外。
流量控制处理对象
流量的处理由三种对象控制,它们是:
- qdisc(排队规则): 内核如果需要通过某个网络接口发送数据包,它都需要按照为这个接口配置的qdisc(排队规则)把数据包加入队列。然后,内核会尽可能多地从qdisc里面取出数据包,把它们交给网络适配器驱动模块。
# 查看现有的队列
root@node1:~# tc -s qdisc ls dev ens32
qdisc pfifo_fast 0: root refcnt 2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
Sent 435417331994 bytes 895868720 pkt (dropped 0, overlimits 0 requeues 302340)
backlog 0b 0p requeues 302340
- class(类别):某些QDisc(排队规则)可以包含一些类别,不同的类别中可以包含更深入的QDisc(排队规则)
- filter(过滤器): 用于为数据包分类,决定它们按照何种QDisc进入队列
安装要求
https://docs.cilium.io/en/v1.8/operations/system_requirements/#features-kernel-matrix
组件
https://docs.cilium.io/en/v1.8/concepts/overview/

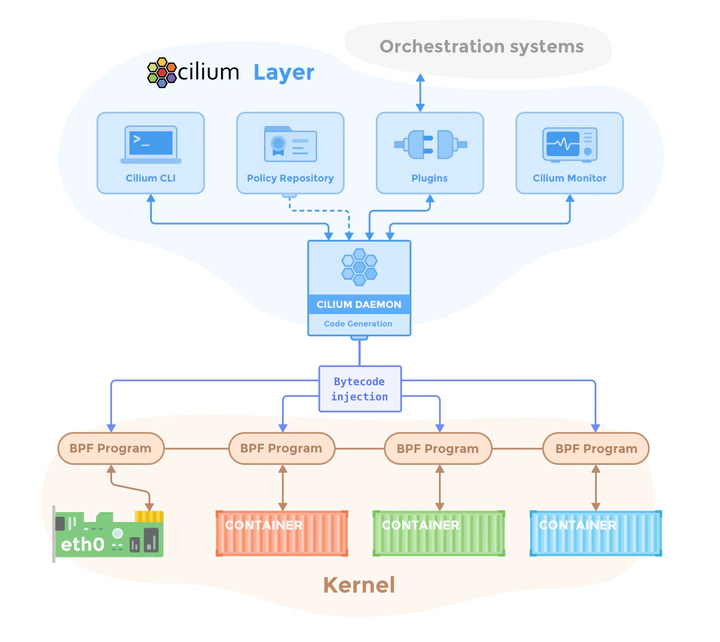
整体架构:控制平面与数据平面
数据平面 (Data Plane):数据平面的核心职责是高效处理实际的网络流量。在 Cilium 中,数据平面主要由运行在每个 Kubernetes 节点(宿主机)Linux 内核中的 eBPF 程序构成。 这些 eBPF 程序负责处理 L3/L4 层的网络连接、执行网络策略、进行负载均衡等。对于 L7 层的策略执行(例如 HTTP、Kafka 策略),Cilium 的数据平面还会集成一个 Envoy 代理。数
控制平面 (Control Plane):控制平面的主要职责是管理和配置数据平面组件。Cilium 的控制平面主要由运行在每个 Kubernetes 节点上的 cilium-agent 守护进程实现。 每个 cilium-agent 都是一个独立的控制平面实例,它连接到 Kubernetes API 服务器,监视集群状态和配置变化(例如 Pod 的创建与删除、网络策略的更新等),并将这些高级配置翻译成具体的 eBPF 程序和规则,下发到其所在节点的数据平面执行。 此外,cilium-agent 还会将其节点上创建的端点(Endpoints)或身份(Identities)等信息以 Kubernetes 自定义资源(CRD)的形式写回 Kubernetes API。
cilium operator
Cilium Agent
Cilium Agent 以 daemonset 的形式运行,因此 Kubernetes 集群的每个节点上都有一个 Cilium agent pod 在运行。该 agent 执行与 Cilium 相关的大部分工作:
- 与 Kubernetes API 服务器交互,同步集群状态
- 与 Linux kernel 交互–加载 eBPF 程序并更新 eBPF map
- 通过文件系统 socket 与 Cilium CNI 插件可执行文件交互,以获得新调度工作负载的通知
- 根据要求的网络策略,按需创建 DNS 和 Envoy Proxy 服务器
- 启用 Hubble 时创建 Hubble gRPC 服务
Cilium CNI Plugin
由 Kubelet 调用在 Pod 的网络命名空间中完成容器网络的管理,包括容器网卡的创建,网关的设置,路由的设置等, 因为依赖 eBPF 的网络能力,这里还会调用 Cilium Agent 的接口,完成 Pod 所需要的 eBPF 程序的编译,挂载,配置,以及和 Pod 相关的 eBPF Maps 的创建和管理。
Hubble Server
主要负责完成 Cilium 网络方案中的观测数据的服务。在 Cilium 运行的数据路径中,会对数据包的处理过程进行记录,最后统一由 Hubble Server 来完成输出,同时提供了 API 来访问这些观测数据
Hubble UI
用于展示 Hubble Server 收集的观测数据,这里会直接连接到 Relay 去查询数据。
Cilium CLI (cilium 和 cilium-dbg)
cilium CLI:这是一个用于快速安装、管理和故障排除运行 Cilium 的 Kubernetes 集群的命令行工具。用户可以使用它来安装 Cilium、检查 Cilium 安装状态、启用/禁用特性(如 ClusterMesh、Hubble)等。
cilium-dbg (Debug Cilium Agent):这是一个与 Cilium Agent 一同安装在每个节点上的命令行工具。它通过与同一节点上运行的 Cilium Agent 的 REST API 交互,允许检查本地 Agent 的状态和各种内部信息。此外,它还提供了直接访问 eBPF 映射以验证其状态的工具。需要注意的是,这个内嵌于 Agent 的 cilium-dbg 与用于集群管理的 cilium CLI 是不同的工具。
https://docs.cilium.io/en/stable/cheatsheet/
目录结构说明
bpf : eBPF datapath收发包路径相关代码,eBPF源码存放目录。
daemon : 各node节点上运行的cilium-agent代码,也是跟内核做交互,处理eBPF相关的核心代码。
pkg : 项目依赖的各种包。 * pkg/bpf : eBPF运行时交互的抽象层 * pkg/datapath datapath交互的抽象层 * pkg/maps eBPF map的描述定义目录 * pkg/monitor eBPF datapath 监控器抽
root@node1:/opt/cilium# tree -L 1 bpf/
bpf/
├── bpf_alignchecker.c # C与Go的消息结构体格式校验
├── bpf_host.c # 物理层的网卡tc ingress\egress相关过滤器
├── bpf_lxc.c # 容器上的网络环境、网络流量管控等
├── bpf_network.c # 网络控制相关
├── bpf_overlay.c # overlay 控制代码
├── bpf_sock.c # sock控制相关,包含流量大小控制、TCP状态变化控制
├── bpf_xdp.c # DP层控制相关
├── complexity-tests
├── COPYING
├── custom
├── ep_config.h
├── filter_config.h
├── include
├── lib
├── LICENSE.BSD-2-Clause
├── LICENSE.GPL-2.0
├── Makefile
├── Makefile.bpf
├── netdev_config.h
├── node_config.h
├── source_names_to_ids.h
└── tests
ipam
https://docs.cilium.io/en/v1.8/concepts/networking/ipam/
cluster-pool 模式( 默认)
https://docs.cilium.io/en/v1.8/concepts/networking/ipam/cluster-pool/
cluster-pool 模式:为每一个 node 分配 pod cidr 交给部署的 cilium-operator 来做.
这个 PodCIDRs 的分配与 Flannel 中的 PodCIDRs 分配 的不同:后者使用 v1.Node 上由 Kubernetes 分配的 podCIDR,这个与 Cilium 的 Kubernetes Host Scope 类似; 而 Cilium 的 cluster-scope 使用的 PodCIDRs 则是由 Cilium operator 来分配和管理的,operator 将分配的 PodCIDR 附加在 v2.CiliumNode 上
(⎈|kubeasz-test:nfs)➜ ~ kubectl get ciliumnode
NAME CILIUMINTERNALIP INTERNALIP AGE
node1 10.233.66.89 172.16.7.30 24d
node2 10.233.64.85 172.16.7.31 24d
node3 10.233.65.143 172.16.7.32 24d
node4 10.233.68.229 172.16.7.33 24d
node5 10.233.67.96 172.16.7.34 24d
node6 10.233.69.139 172.16.7.35 23d
(⎈|kubeasz-test:monitoring)➜ ~ kubectl get cn node1 -o yaml
apiVersion: cilium.io/v2
kind: CiliumNode
metadata:
creationTimestamp: "2025-08-20T07:05:10Z"
generation: 33
labels:
beta.kubernetes.io/arch: amd64
beta.kubernetes.io/os: linux
kubernetes.io/arch: amd64
kubernetes.io/hostname: node1
kubernetes.io/os: linux
node-role.kubernetes.io/control-plane: ""
node.kubernetes.io/exclude-from-external-load-balancers: ""
openebs.io/nodename: node1
name: node1
ownerReferences:
- apiVersion: v1
kind: Node
name: node1
uid: add1b2b6-5a4d-4882-9c52-be844c221253
resourceVersion: "13826717"
uid: 34624aac-196e-4e8a-a9d7-c8f0d3813f0e
spec:
addresses:
- ip: 172.16.7.30
type: InternalIP
- ip: 10.233.66.89
type: CiliumInternalIP
alibaba-cloud: {}
azure: {}
bootid: 5c26c664-8df0-4385-90f6-ace4c9cc9e80
encryption: {}
eni: {}
health:
ipv4: 10.233.66.85
ingress: {}
ipam:
podCIDRs:
- 10.233.66.0/24
pools: {}
status:
alibaba-cloud: {}
azure: {}
eni: {}
ipam:
operator-status: {}
crd
https://docs.cilium.io/en/v1.8/concepts/networking/ipam/crd/
路由方式
https://docs.cilium.io/en/stable/network/concepts/routing/
vxlan 方式
开启方式
apiVersion: v1
kind: ConfigMap
metadata:
name: cilium-config
namespace: kube-system
data:
routing-mode: tunnel
tunnel-protocol: vxlan
root@node6:~# ip --detail link show cilium_vxlan
7: cilium_vxlan: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether ba:41:db:f7:e0:e1 brd ff:ff:ff:ff:ff:ff promiscuity 0 allmulti 0 minmtu 68 maxmtu 65535
vxlan external id 0 srcport 0 0 dstport 8472 nolearning ttl auto ageing 300 udpcsum noudp6zerocsumtx noudp6zerocsumrx addrgenmode eui64 numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 tso_max_size 65536 tso_max_segs 65535 gro_max_size 65536
Cilium Agent 在启动的时候,会初始化这个虚拟的网络设备。主要的作用就是完成在 overlay 网络模式下,基于 vxlan/vtep 完成跨主机的网络数据通信。 Cilium 使用 UDP 8472 端口作为 vtep 端点的服务。 vxlan 的数据包路由,也是通过 Kernel 的路由子系统完成路由发现,最后通过物理网卡,完成跨主机的 overlay 网络。cilium_vxlan 挂载的 eBPF 程序通过 tc 的方式完成,包括 from-overlay 和 to-overlay,
root@node6:/home/cilium# ip route
default via 172.16.0.254 dev ens32 proto static
10.233.64.0/24 via 10.233.69.139 dev cilium_host proto kernel src 10.233.69.139 mtu 1450
10.233.65.0/24 via 10.233.69.139 dev cilium_host proto kernel src 10.233.69.139 mtu 1450
10.233.66.0/24 via 10.233.69.139 dev cilium_host proto kernel src 10.233.69.139 mtu 1450
10.233.67.0/24 via 10.233.69.139 dev cilium_host proto kernel src 10.233.69.139 mtu 1450
10.233.68.0/24 via 10.233.69.139 dev cilium_host proto kernel src 10.233.69.139 mtu 1450
10.233.69.0/24 via 10.233.69.139 dev cilium_host proto kernel src 10.233.69.139
10.233.69.139 dev cilium_host proto kernel scope link
172.16.0.0/16 dev ens32 proto kernel scope link src 172.16.7.35
cilium_host/cilium_net:
root@node6:/home/cilium# ip addr ls
5: cilium_net@cilium_host: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether be:ef:8a:3c:d5:99 brd ff:ff:ff:ff:ff:ff
inet6 fe80::bcef:8aff:fe3c:d599/64 scope link
valid_lft forever preferred_lft forever
6: cilium_host@cilium_net: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether ea:5e:98:86:cd:e2 brd ff:ff:ff:ff:ff:ff
inet 10.233.69.139/32 scope global cilium_host
valid_lft forever preferred_lft forever
inet6 fe80::e85e:98ff:fe86:cde2/64 scope link
valid_lft forever preferred_lft forever
cilium_host 有设置 ip 地址,这个 ip 地址会作为 Pod 的网关,可以查看 Pod 的路由信息,看到对应的网关地址就是 cilium_host 的 ip 地址。
# cilium_host 和 cilium_net 是一对
root@node6:/home/cilium# ip link ls
5: cilium_net@cilium_host: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether be:ef:8a:3c:d5:99 brd ff:ff:ff:ff:ff:ff
6: cilium_host@cilium_net: <BROADCAST,MULTICAST,NOARP,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether ea:5e:98:86:cd:e2 brd ff:ff:ff:ff:ff:ff
网卡 lxc-xxx/eth0: 每一个 Pod 都会有的一对 veth pair。这也是容器网络中最常见 Linux 提供的虚拟网络设备。一端在主机的网络空间,一端在容器的网络空间。
其中 eth0 是容器端的,lxc-xxx 是主机端的。eth0 有自己的 ip 地址,lxc-xxx 是没有 ip 地址的。对于容器的出口流量,使用了 tc ingress 的方式,在 lxc-xxx 主机端的设备上挂载了 eBPF 程序,程序的 Section 是 from-container,
Host Routing 本地路由
创建网络的过程
- 创建网络设备(例如 veth-pair, IPVLAN dev)
- 分配IP地址
- 配置Pod的网络配置(例如IP地址,路由表项,sysctl)
- 创建Endpoint对象(作用域仅限于Node内部),通过Cilium agent的API
- 创建CiliumEndpoint对象(通过k8s的apiserver,创建一个CRD)
- 通过集群的kvstore,为Endpoint获取/分配一个identity
- 计算处理 network policy
- 存储IP相关的信息(例如 IP与Identity之间的映射)到kvstore内
- 编译,生成BPF程序代码并且加载到内核中执行
// plugins/cilium-cni/cmd/cmd.go
func (cmd *Cmd) Add(args *skel.CmdArgs) (err error) {
// 1. 从args中加载相应的网络配置
n, err := types.LoadNetConf(args.StdinData)
if err != nil {
return fmt.Errorf("unable to parse CNI configuration %q: %w", string(args.StdinData), err)
}
// ...
cniArgs := &types.ArgsSpec{}
if err = cniTypes.LoadArgs(args.Args, cniArgs); err != nil {
return fmt.Errorf("unable to extract CNI arguments: %w", err)
}
scopedLogger = buildLogAttrsWithCNIArgs(scopedLogger, cniArgs)
c, err := client.NewDefaultClientWithTimeout(defaults.ClientConnectTimeout)
if err != nil {
return fmt.Errorf("unable to connect to Cilium agent: %w", client.Hint(err))
}
conf, err := getConfigFromCiliumAgent(c)
if err != nil {
return err
}
// ...
for _, epConf := range configs {
if err = ns.Do(func() error {
return link.DeleteByName(epConf.IfName())
}); err != nil {
return fmt.Errorf("failed removing interface %q from namespace %q: %w",
epConf.IfName(), args.Netns, err)
}
var ipam *models.IPAMResponse
var releaseIPsFunc func(context.Context)
// 获取 ipam 信息
if conf.IpamMode == ipamOption.IPAMDelegatedPlugin {
ipam, releaseIPsFunc, err = allocateIPsWithDelegatedPlugin(context.TODO(), conf, n, args.StdinData)
} else {
ipam, releaseIPsFunc, err = allocateIPsWithCiliumAgent(scopedLogger, c, cniArgs, epConf.IPAMPool())
}
// release addresses on failure
defer func() {
if err != nil && releaseIPsFunc != nil {
releaseIPsFunc(context.TODO())
}
}()
if err != nil {
return err
}
if err = connector.SufficientAddressing(ipam.HostAddressing); err != nil {
return fmt.Errorf("IP allocation addressing is insufficient: %w", err)
}
if !ipv6IsEnabled(ipam) && !ipv4IsEnabled(ipam) {
return errors.New("IPAM did provide neither IPv4 nor IPv6 address")
}
state, ep, err := epConf.PrepareEndpoint(ipam)
if err != nil {
return fmt.Errorf("unable to prepare endpoint configuration: %w", err)
}
cniID := ep.ContainerID + ":" + ep.ContainerInterfaceName
linkConfig := connector.LinkConfig{
GROIPv6MaxSize: int(conf.GROMaxSize),
GSOIPv6MaxSize: int(conf.GSOMaxSize),
GROIPv4MaxSize: int(conf.GROIPV4MaxSize),
GSOIPv4MaxSize: int(conf.GSOIPV4MaxSize),
DeviceMTU: int(conf.DeviceMTU),
}
var hostLink, epLink netlink.Link
var tmpIfName string
var l2Mode bool
// 3. 根据配置的模式, 选择对应的设备初始化方式
switch conf.DatapathMode {
case datapathOption.DatapathModeVeth:
l2Mode = true
hostLink, epLink, tmpIfName, err = connector.SetupVeth(scopedLogger, cniID, linkConfig, sysctl)
case datapathOption.DatapathModeNetkit, datapathOption.DatapathModeNetkitL2:
l2Mode = conf.DatapathMode == datapathOption.DatapathModeNetkitL2
hostLink, epLink, tmpIfName, err = connector.SetupNetkit(scopedLogger, cniID, linkConfig, l2Mode, sysctl)
}
if err != nil {
return fmt.Errorf("unable to set up link on host side: %w", err)
}
defer func() {
if err != nil {
if err2 := netlink.LinkDel(hostLink); err2 != nil {
scopedLogger.Warn(
"Failed to clean up and delete link",
logfields.Error, err2,
logfields.Veth, hostLink.Attrs().Name,
)
}
}
}()
iface := &cniTypesV1.Interface{
Name: hostLink.Attrs().Name,
}
if l2Mode {
iface.Mac = hostLink.Attrs().HardwareAddr.String()
}
res.Interfaces = append(res.Interfaces, iface)
// CNI插件将对端veth放置到容器所在的网络空间中
if err := netlink.LinkSetNsFd(epLink, ns.FD()); err != nil {
return fmt.Errorf("unable to move netkit pair %q to netns %s: %w", epLink, args.Netns, err)
}
// 重命名对端设备,会将容器内的veth从tmp53057 重命名为eth0
err = connector.RenameLinkInRemoteNs(ns, tmpIfName, epConf.IfName())
if err != nil {
return fmt.Errorf("unable to set up netkit on container side: %w", err)
}
if l2Mode {
ep.Mac = epLink.Attrs().HardwareAddr.String()
ep.HostMac = hostLink.Attrs().HardwareAddr.String()
}
ep.InterfaceIndex = int64(hostLink.Attrs().Index)
ep.InterfaceName = hostLink.Attrs().Name
var (
ipConfig *cniTypesV1.IPConfig
ipv6Config *cniTypesV1.IPConfig
routes []*cniTypes.Route
)
// ...
if ipv4IsEnabled(ipam) && conf.Addressing.IPV4 != nil {
ep.Addressing.IPV4 = ipam.Address.IPV4
ep.Addressing.IPV4PoolName = ipam.Address.IPV4PoolName
ep.Addressing.IPV4ExpirationUUID = ipam.IPV4.ExpirationUUID
// 准备 IP 配置信息
ipConfig, routes, err = prepareIP(ep.Addressing.IPV4, state, int(conf.RouteMTU))
if err != nil {
return fmt.Errorf("unable to prepare IP addressing for %s: %w", ep.Addressing.IPV4, err)
}
// set the addresses interface index to that of the container-side interface
ipConfig.Interface = cniTypesV1.Int(len(res.Interfaces))
res.IPs = append(res.IPs, ipConfig)
res.Routes = append(res.Routes, routes...)
}
if needsEndpointRoutingOnHost(conf) {
if ipam.IPV4 != nil && ipConfig != nil {
err = interfaceAdd(scopedLogger, ipConfig, ipam.IPV4, conf)
if err != nil {
return fmt.Errorf("unable to setup interface datapath: %w", err)
}
}
if ipam.IPV6 != nil && ipv6Config != nil {
err = interfaceAdd(scopedLogger, ipv6Config, ipam.IPV6, conf)
if err != nil {
return fmt.Errorf("unable to setup interface datapath: %w", err)
}
}
}
var macAddrStr string
if err = ns.Do(func() error {
if err := reserveLocalIPPorts(conf, sysctl); err != nil {
scopedLogger.Warn(
"Unable to reserve local ip ports",
logfields.Error, err,
)
}
// 4. 分配IP给Pod的网络设备
macAddrStr, err = configureIface(scopedLogger, ipam, epConf.IfName(), state)
return err
}); err != nil {
return fmt.Errorf("unable to configure interfaces in container namespace: %w", err)
}
var cookie uint64
if getNetnsCookie {
if err = ns.Do(func() error {
cookie, err = netns.GetNetNSCookie()
return err
}); err != nil {
if errors.Is(err, unix.ENOPROTOOPT) {
getNetnsCookie = false
}
scopedLogger.Info(
"Unable to get netns cookie",
logfields.Error, err,
logfields.ContainerID, args.ContainerID,
)
}
}
ep.NetnsCookie = strconv.FormatUint(cookie, 10)
// Specify that endpoint must be regenerated synchronously. See GH-4409.
ep.SyncBuildEndpoint = true
var newEp *models.Endpoint
// 创建endpoint对象
if newEp, err = c.EndpointCreate(ep); err != nil {
scopedLogger.Warn(
"Unable to create endpoint",
logfields.Error, err,
logfields.ContainerID, ep.ContainerID,
)
return fmt.Errorf("unable to create endpoint: %w", err)
}
if newEp != nil && newEp.Status != nil && newEp.Status.Networking != nil && newEp.Status.Networking.Mac != "" {
// Set the MAC address on the interface in the container namespace
if conf.DatapathMode != datapathOption.DatapathModeNetkit {
err = ns.Do(func() error {
return mac.ReplaceMacAddressWithLinkName(args.IfName, newEp.Status.Networking.Mac)
})
if err != nil {
return fmt.Errorf("unable to set MAC address on interface %s: %w", args.IfName, err)
}
}
macAddrStr = newEp.Status.Networking.Mac
}
if err = ns.Do(func() error {
return configureCongestionControl(conf, sysctl)
}); err != nil {
return fmt.Errorf("unable to configure congestion control: %w", err)
}
res.Interfaces = append(res.Interfaces, &cniTypesV1.Interface{
Name: epConf.IfName(),
Mac: macAddrStr,
Sandbox: args.Netns,
})
scopedLogger.Debug(
"Endpoint successfully created",
logfields.Error, err,
logfields.ContainerID, ep.ContainerID,
)
}
return cniTypes.PrintResult(res, n.CNIVersion)
}
一个Endpoint其实就是一个 “命名空间下的某个网络接口”,而cilium将会把相应的网络管理策略作用在这样的接口上。
~ kubectl get ciliumendpoint -n monitoring
NAME SECURITY IDENTITY ENDPOINT STATE IPV4 IPV6
alertmanager-main-0 17144 ready 10.233.67.49
alertmanager-main-1 17144 ready 10.233.68.15
// pkg/endpoint/api/endpoint_api_manager.go
// HTTP Handle 创建Endpoint对象
func (m *endpointAPIManager) CreateEndpoint(ctx context.Context, epTemplate *models.EndpointChangeRequest) (*endpoint.Endpoint, int, error) {
// ...
// We don't need to create the endpoint with the labels. This might cause
// the endpoint regeneration to not be triggered further down, with the
// ep.UpdateLabels or the ep.RunMetadataResolver, because the regeneration
// is only triggered in case the labels are changed, which they might not
// change because NewEndpointFromChangeModel would contain the
// epTemplate.Labels, the same labels we would be calling ep.UpdateLabels or
// the ep.RunMetadataResolver.
apiLabels := labels.NewLabelsFromModel(epTemplate.Labels)
epTemplate.Labels = nil
ep, err := m.endpointCreator.NewEndpointFromChangeModel(ctx, epTemplate)
if err != nil {
return invalidDataError(ep, fmt.Errorf("unable to parse endpoint parameters: %w", err))
}
oldEp := m.endpointManager.LookupCiliumID(ep.ID)
if oldEp != nil {
return invalidDataError(ep, fmt.Errorf("endpoint ID %d already exists", ep.ID))
}
oldEp = m.endpointManager.LookupCNIAttachmentID(ep.GetCNIAttachmentID())
if oldEp != nil {
return invalidDataError(ep, fmt.Errorf("endpoint for CNI attachment ID %s already exists", ep.GetCNIAttachmentID()))
}
// 这个端点的ID并校验它是否合法
var checkIDs []string
if ep.IPv4.IsValid() {
checkIDs = append(checkIDs, endpointid.NewID(endpointid.IPv4Prefix, ep.IPv4.String()))
}
if ep.IPv6.IsValid() {
checkIDs = append(checkIDs, endpointid.NewID(endpointid.IPv6Prefix, ep.IPv6.String()))
}
for _, id := range checkIDs {
oldEp, err := m.endpointManager.Lookup(id)
if err != nil {
return invalidDataError(ep, err)
} else if oldEp != nil {
return invalidDataError(ep, fmt.Errorf("IP %s is already in use", id))
}
}
if err = endpoint.APICanModify(ep); err != nil {
return invalidDataError(ep, err)
}
infoLabels := labels.NewLabelsFromModel([]string{})
if len(apiLabels) > 0 {
if lbls := apiLabels.FindReserved(); lbls != nil {
return invalidDataError(ep, fmt.Errorf("not allowed to add reserved labels: %s", lbls))
}
apiLabels, _ = labelsfilter.Filter(apiLabels)
if len(apiLabels) == 0 {
return invalidDataError(ep, fmt.Errorf("no valid labels provided"))
}
}
var cancel context.CancelFunc
ctx, cancel = context.WithCancel(ctx)
m.endpointCreations.NewCreateRequest(ep, cancel)
defer m.endpointCreations.EndCreateRequest(ep)
identityLbls := maps.Clone(apiLabels)
if ep.K8sNamespaceAndPodNameIsSet() && m.clientset.IsEnabled() {
pod, k8sMetadata, err := m.handleOutdatedPodInformer(ctx, ep)
if errors.Is(err, endpointmetadata.ErrPodStoreOutdated) {
// ...
}
if err != nil {
ep.Logger("api").Warn("Unable to fetch kubernetes labels", logfields.Error, err)
} else {
ep.SetPod(pod)
ep.SetK8sMetadata(k8sMetadata.ContainerPorts)
identityLbls.MergeLabels(k8sMetadata.IdentityLabels)
infoLabels.MergeLabels(k8sMetadata.InfoLabels)
if _, ok := pod.Annotations[bandwidth.IngressBandwidth]; ok && !m.bandwidthManager.Enabled() {
m.logger.Warn("Endpoint has bandwidth annotation, but BPF bandwidth manager is disabled. This annotation is ignored.",
logfields.K8sPodName, epTemplate.K8sNamespace+"/"+epTemplate.K8sPodName,
logfields.Annotation, bandwidth.IngressBandwidth,
logfields.Annotations, pod.Annotations,
)
}
if _, ok := pod.Annotations[bandwidth.EgressBandwidth]; ok && !m.bandwidthManager.Enabled() {
m.logger.Warn("Endpoint has %s annotation, but BPF bandwidth manager is disabled. This annotation is ignored.",
logfields.K8sPodName, epTemplate.K8sNamespace+"/"+epTemplate.K8sPodName,
logfields.Annotation, bandwidth.EgressBandwidth,
logfields.Annotations, pod.Annotations,
)
}
if hwAddr, ok := pod.Annotations[annotation.PodAnnotationMAC]; !ep.GetDisableLegacyIdentifiers() && ok {
mac, err := mac.ParseMAC(hwAddr)
if err != nil {
m.logger.Error("Unable to parse MAC address",
logfields.Error, err,
logfields.K8sPodName, epTemplate.K8sNamespace+"/"+epTemplate.K8sPodName,
)
return invalidDataError(ep, err)
}
ep.SetMac(mac)
}
}
}
// The following docs describe the cases where the init identity is used:
// http://docs.cilium.io/en/latest/policy/lifecycle/#init-identity
if len(identityLbls) == 0 {
// If the endpoint has no labels, give the endpoint a special identity with
// label reserved:init so we can generate a custom policy for it until we
// get its actual identity.
identityLbls = labels.Labels{
labels.IDNameInit: labels.NewLabel(labels.IDNameInit, "", labels.LabelSourceReserved),
}
}
// e.ID assigned here
err = m.endpointManager.AddEndpoint(ep)
if err != nil {
return m.errorDuringCreation(ep, fmt.Errorf("unable to insert endpoint into manager: %w", err))
}
var regenTriggered bool
if ep.K8sNamespaceAndPodNameIsSet() && m.clientset.IsEnabled() {
// We need to refetch the pod labels again because we have just added
// the endpoint into the endpoint manager. If we have received any pod
// events, more specifically any events that modified the pod labels,
// between the time the pod was created and the time it was added
// into the endpoint manager, the pod event would not have been processed
// since the pod event handler would not find the endpoint for that pod
// in the endpoint manager. Thus, we will fetch the labels again
// and update the endpoint with these labels.
// Wait for the regeneration to be triggered before continuing.
regenTriggered = ep.RunMetadataResolver(false, true, apiLabels, m.endpointMetadata.FetchK8sMetadataForEndpoint)
} else {
regenTriggered = ep.UpdateLabels(ctx, labels.LabelSourceAny, identityLbls, infoLabels, true)
}
select {
case <-ctx.Done():
return m.errorDuringCreation(ep, fmt.Errorf("request cancelled while resolving identity"))
default:
}
if !regenTriggered {
regenMetadata := ®eneration.ExternalRegenerationMetadata{
Reason: "Initial build on endpoint creation",
ParentContext: ctx,
RegenerationLevel: regeneration.RegenerateWithDatapath,
}
build, err := ep.SetRegenerateStateIfAlive(regenMetadata)
if err != nil {
return m.errorDuringCreation(ep, err)
}
if build {
ep.Regenerate(regenMetadata)
}
}
if epTemplate.SyncBuildEndpoint {
if err := ep.WaitForFirstRegeneration(ctx); err != nil {
return m.errorDuringCreation(ep, err)
}
}
// The endpoint has been successfully created, stop the expiration
// timers of all attached IPs
if addressing := epTemplate.Addressing; addressing != nil {
if uuid := addressing.IPV4ExpirationUUID; uuid != "" {
if ip := net.ParseIP(addressing.IPV4); ip != nil {
pool := ipam.PoolOrDefault(addressing.IPV4PoolName)
if err := m.ipam.StopExpirationTimer(ip, pool, uuid); err != nil {
return m.errorDuringCreation(ep, err)
}
}
}
if uuid := addressing.IPV6ExpirationUUID; uuid != "" {
if ip := net.ParseIP(addressing.IPV6); ip != nil {
pool := ipam.PoolOrDefault(addressing.IPV6PoolName)
if err := m.ipam.StopExpirationTimer(ip, pool, uuid); err != nil {
return m.errorDuringCreation(ep, err)
}
}
}
}
return ep, 0, nil
}
创建CiliumEndpoint
func (mgr *endpointManager) AddEndpoint(ep *endpoint.Endpoint) (err error) {
// ..
err = mgr.expose(ep)
// ...
}
func (mgr *endpointManager) expose(ep *endpoint.Endpoint) error {
newID, err := mgr.allocateID(ep.ID)
if err != nil {
return err
}
mgr.mutex.Lock()
// Get a copy of the identifiers before exposing the endpoint
identifiers := ep.Identifiers()
ep.PolicyMapPressureUpdater = mgr.policyMapPressure
ep.Start(newID)
mgr.mcastManager.AddAddress(ep.IPv6)
mgr.updateIDReferenceLocked(ep)
mgr.updateReferencesLocked(ep, identifiers)
mgr.mutex.Unlock()
ep.InitEndpointHealth(mgr.health)
mgr.RunK8sCiliumEndpointSync(ep, ep.GetReporter("cep-k8s-sync"))
return nil
}