k8s 集群部署
部署工具
- github.com/kubernetes-sigs/kubespray: 使用 ansible 作为配置和编排的基础, 依赖 kubeadm
- github.com/kubernetes/kops: 与云平台绑定深,比如 AWS (Amazon Web Services) and GCP (Google Cloud Platform)
- github.com/kubernetes/kubeadm
- github.com/easzlab/kubeasz: 使用 ansible 脚本安装K8S集群,方便国内网络环境
集群规划
网段规划
安装K8S集群安装时会涉及到三个网段:
- 宿主机网段:就是安装k8s的服务器
- Pod网段:k8s Pod的网段,相当于容器的IP
- Service网段:k8s service网段,service用于集群容器通信
需要注意的是这三个网段不能有任何交叉, 可用工具:在线IP地址/子网掩码计算与转换工具
系统内核参数设置
# https://github.com/easzlab/kubeasz/blob/3.6.5/roles/prepare/templates/95-k8s-sysctl.conf.j2
net.ipv4.ip_forward = 1 # 启用ip转发另外也防止docker改变iptables
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-arptables = 1
net.ipv4.tcp_tw_reuse = 0
net.core.somaxconn = 32768
net.netfilter.nf_conntrack_max=1000000
vm.swappiness = 0
vm.max_map_count=655360 # 限制一个进程可以拥有的VMA(虚拟内存区域)的数量,一个更大的值对于 elasticsearch、mongo 或其他 mmap 用户来说非常有用
fs.file-max=6553600
{% if PROXY_MODE == "ipvs" %}
net.ipv4.tcp_keepalive_time = 600
net.ipv4.tcp_keepalive_intvl = 30
net.ipv4.tcp_keepalive_probes = 10
{% endif %}
tcp 相关
创建过程:从Client调用connect(),到Server侧accept()成功返回这一过程中的TCP状态转换
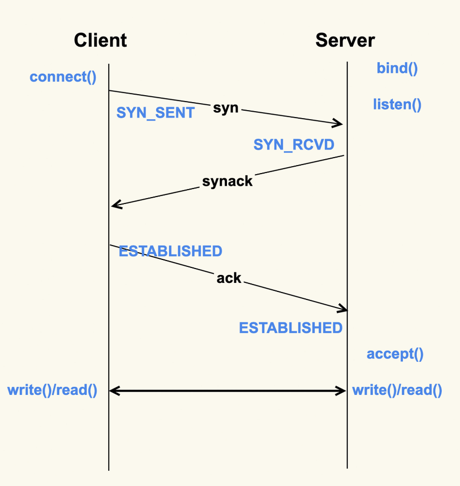
- 半连接: 收到了SYN后还没有回复SYNACK的连接.
- TCP全连接(complete): Client在收到Server的SYNACK包后,就会发出ACK,Server收到该ACK后,三次握手就完成了,即产生了一个
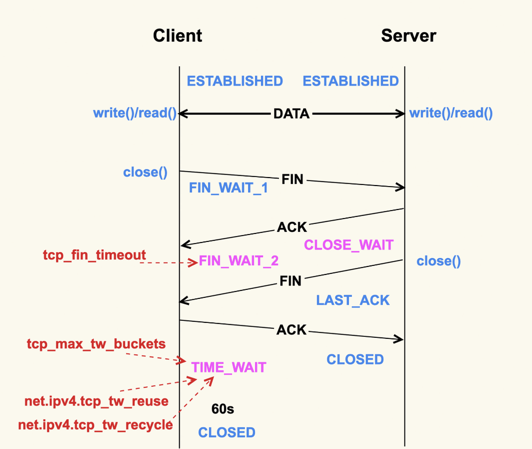
- TIME_WAIT状态存在的意义是:最后发送的这个ACK包可能会被丢弃掉或者有延迟,这样对端就会再次发送FIN包。如果不维持TIME_WAIT这个状态,那么再次收到对端的FIN包后,本端就会回一个Reset包,这可能会产生一些异常。
net.ipv4.tcp_max_syn_backlog = 16384
Server每收到一个新的SYN包,都会创建一个半连接,然后把该半连接加入到半连接队列(syn queue)中。syn queue的长度就是tcp_max_syn_backlog这个配置项来决定的,当系统中积压的半连接个数超过了该值后,新的SYN包就会被丢弃。 对于服务器而言,可能瞬间会有非常多的新建连接,所以我们可以适当地调大该值,以免SYN包被丢弃而导致Client收不到SYNACK
net.ipv4.tcp_syncookies = 1
Server中积压的半连接较多,也有可能是因为有些恶意的Client在进行SYN Flood攻击。 典型的SYN Flood攻击如下:Client高频地向Server发SYN包,并且这个SYN包的源IP地址不停地变换,那么Server每次接收到一个新的SYN后,都会给它分配一个半连接,Server的SYNACK根据之前的SYN包找到的是错误的Client IP, 所以也就无法收到Client的ACK包,导致无法正确建立TCP连接,这就会让Server的半连接队列耗尽,无法响应正常的SYN包。
在Server收到SYN包时,不去分配资源来保存Client的信息,而是根据这个SYN包计算出一个Cookie值,然后将Cookie记录到SYNACK包中发送出去。 对于正常的连接,该Cookies值会随着Client的ACK报文被带回来。然后Server再根据这个Cookie检查这个ACK包的合法性,如果合法,才去创建新的TCP连接。通过这种处理,SYN Cookies可以防止部分SYN Flood攻击
net.ipv4.tcp_syn_retries = 2
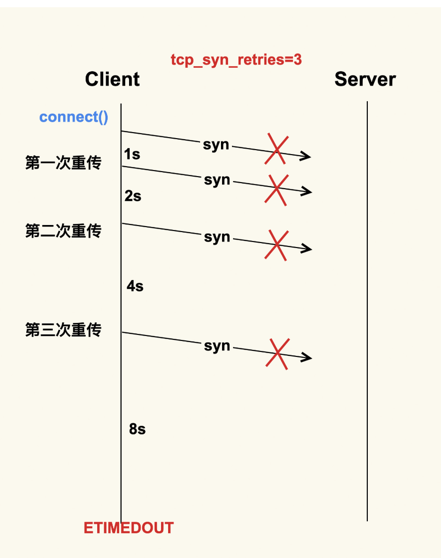
首先Client会给Server发送一个SYN包,但是该SYN包可能会在传输过程中丢失,或者因为其他原因导致Server无法处理,此时Client这一侧就会触发超时重传机制。但是也不能一直重传下去,重传的次数也是有限制的,这就是tcp_syn_retries这个配置项来决定的
我们在生产环境上就遇到过这种情况,Server因为某些原因被下线,但是Client没有被通知到,所以Client的connect()被阻塞127s才去尝试连接一个新的Server, 这么长的超时等待时间对于应用程序而言是很难接受的。
所以通常情况下,我们都会将数据中心内部服务器的tcp_syn_retries给调小,这里推荐设置为2,来减少阻塞的时间。
同理重传策略 net.ipv4.tcp_synack_retries = 2
net.core.somaxconn = 16384
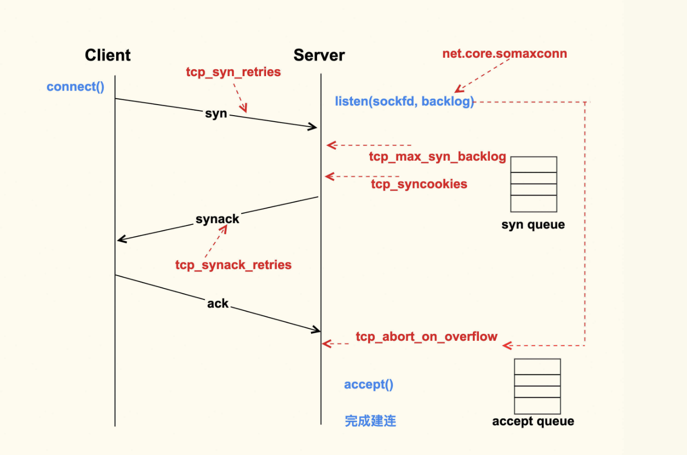
Client在收到Server的SYNACK包后,就会发出ACK,Server收到该ACK后,三次握手就完成了,即产生了一个TCP全连接(complete),它会被添加到全连接队列(accept queue)中。
然后Server就会调用accept()来完成TCP连接的建立全连接队列(accept queue)的长度有限制,目的就是为了防止Server不能及时调用accept()而浪费太多的系统资源. 全连接队列(accept queue)的长度是由listen(sockfd, backlog)这个函数里的backlog控制的,而该backlog的最大值则是somaxconn
somaxconn在5.4之前的内核中,默认都是128(5.4开始调整为了默认4096).
当服务器中积压的全连接个数超过该值后,新的全连接就会被丢弃掉。Server在将新连接丢弃时,有的时候需要发送reset来通知Client,这样Client就不会再次重试了。 不过,默认行为是直接丢弃不去通知Client。至于是否需要给Client发送reset,是由tcp_abort_on_overflow这个配置项来控制的,该值默认为0,即不发送reset给Client。
net.ipv4.tcp_fin_timeout = 2
FIN_WAIT_2状态,TCP进入到这个状态后,如果本端迟迟收不到对端的FIN包,那就会一直处于这个状态,于是就会一直消耗系统资源。 Linux为了防止这种资源的开销,设置了这个状态的超时时间tcp_fin_timeout,默认为60s,超过这个时间后就会自动销毁该连接。
至于本端为何迟迟收不到对端的FIN包,通常情况下都是因为对端机器出了问题,或者是因为太繁忙而不能及时close()。
net.ipv4.tcp_tw_reuse = 1
TIME_WAIT的默认存活时间在Linux上是60s(TCP_TIMEWAIT_LEN),这个时间对于数据中心而言可能还是有些长了,所以有的时候也会修改内核做些优化来减小该值,或者将该值设置为可通过sysctl来调节。
TIME_WAIT状态存在这么长时间,也是对系统资源的一个浪费,所以系统也有配置项来限制该状态的最大个数,该配置选项就是tcp_max_tw_buckets。对于数据中心而言,网络是相对很稳定的,基本不会存在FIN包的异常,所以建议将该值调小一些:
net.ipv4.tcp_max_tw_buckets = 10000
Client关闭跟Server的连接后,也有可能很快再次跟Server之间建立一个新的连接,而由于TCP端口最多只有65536个,如果不去复用处于TIME_WAIT状态的连接,就可能在快速重启应用程序时,出现端口被占用而无法创建新连接的情况。所以建议你打开复用TIME_WAIT的选项
还有另外一个选项tcp_tw_recycle来控制TIME_WAIT状态,但是该选项是很危险的,因为它可能会引起意料不到的问题,比如可能会引起NAT环境下的丢包问题。 net.ipv4.tcp_tw_recycle = 0 因为打开该选项后引起了太多的问题,所以4.12内核开始就索性删掉了这个配置选项
系统预留
默认情况下 Pod 能够使用节点全部可用容量,同样就会伴随一个新的问题,pod消耗的内存会挤占掉系统服务本身的资源,这就好比我们在宿主机上运行java服务一样,会出现java程序将宿主机上的资源(内存、cpu)耗尽,从而导致系统登陆不上或者卡顿现象。

Node Allocatable Resource = Node Capacity - Kube-reserved - system-reserved - eviction-threshold
- Node Capacity:Node的所有硬件资源,kube-reserved是给kube组件预留的资源
- Kube-reserved:kube 组件预留的资源
- system-reserved:给system进程预留的资源
- eviction-threshold(阈值):kubelet eviction(收回)的阈值设定
# kubeasz/roles/kube-node/templates/kubelet-config.yaml.j2
# 配置硬驱逐阈值
evictionHard:
imagefs.available: 15%
memory.available: 300Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
enforceNodeAllocatable:
- pods
{% if KUBE_RESERVED_ENABLED == "yes" %}
- kube-reserved
{% endif %}
{% if SYS_RESERVED_ENABLED == "yes" %}
- system-reserved
{% endif %}
# 配置 kube 资源预留
{% if KUBE_RESERVED_ENABLED == "yes" %}
kubeReservedCgroup: /podruntime.slice
kubeReserved:
cpu: 500m
memory: 1000Mi
pid: "1000"
{% endif %}
# 配置系统资源预留
{% if SYS_RESERVED_ENABLED == "yes" %}
systemReservedCgroup: /system.slice
systemReserved:
cpu: 500m
memory: 1000Mi
pid: "5000"
{% endif %}
如果没有资源预留,k8s 默认认为宿主机上所有的资源(RAM、CPU)都是可以分配给 Pod 类进程。 因为非 Pod 类进程也需要占用一定的资源,当 Pod 创建很多时,就有可能出现资源不足的情况。宿主机中kubelet、kube-proxy 等进程被 kill 掉,最后导致整个 Node 节点不可用。 我们知道,当 Pod 里面内存不足时,会触发 Cgroup 把 Pod 里面的进程杀死; 当系统内存不足时,就有可能触发系统OOM,这时候根据 oom score 来确定优先杀死哪个进程,而 oom_score_adj 又是影响 oom score 的重要参数,其值越低,表示 oom 的优先级越低.
kubeasz 使用
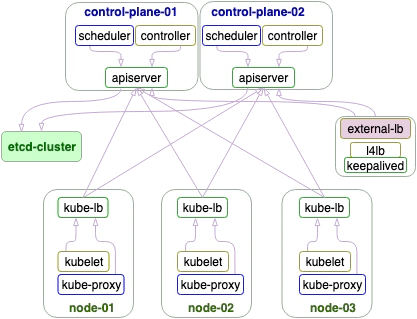
架构图
AllinOne部署,然后再添加 master,node.
镜像仓库
方式一: registry:2 镜像
# 这里使用 registry:2 镜像
[root@master-01 ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4c7d11de49e5 registry:2 "/entrypoint.sh /etc…" 13 minutes ago Up 13 minutes local_registry
ca88938b4d45 easzlab/kubeasz:3.6.5 "tail -f /dev/null" 3 months ago Up 2 weeks kubeasz
# 查询镜像分类
[root@master-01 ~]# curl http://easzlab.io.local:5000/v2/_catalog | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 576 100 576 0 0 56860 0 --:--:-- --:--:-- --:--:-- 64000
{
"repositories": [
"calico/cni",
"calico/kube-controllers",
"calico/node",
"coredns/coredns",
"easzlab/k8s-dns-node-cache",
"easzlab/metrics-server",
"easzlab/pause",
"flannel/flannel",
"flannel/flannel-cni-plugin",
"grafana/grafana",
"kubernetesui/dashboard",
"kubernetesui/metrics-scraper",
"prometheus/alertmanager",
"prometheus/grafana",
"prometheus/k8s-sidecar",
"prometheus/kube-state-metrics",
"prometheus/kube-webhook-certgen",
"prometheus/node-exporter",
"prometheus/prometheus",
"prometheus/prometheus-config-reloader",
"prometheus/prometheus-operator",
"rancher/local-path-provisioner"
]
}
# 查询镜像
[root@master-01 ~]# curl http://easzlab.io.local:5000/v2/calico/cni/tags/list | jq .
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 41 100 41 0 0 8577 0 --:--:-- --:--:-- --:--:-- 10250
{
"name": "calico/cni",
"tags": [
"v3.28.2"
]
}
方式二: 单机安装harbor 服务
特性包括:友好的用户界面,基于角色的访问控制,水平扩展,同步复制,AD/LDAP集成以及审计日志等。
https://github.com/easzlab/kubeasz/blob/3.6.6/docs/guide/harbor.md

结构:https://github.com/goharbor/harbor/wiki/Architecture-Overview-of-Harbor
kubeadm 使用
https://kubernetes.io/zh-cn/docs/reference/setup-tools/kubeadm/
- kubeadm init 创建新的控制平面节点
- kubeadm join 将节点快速连接到指定的控制平面
# kubeadm join phase 子命令
root@node1:/tmp/releases# ./kubeadm-v1.31.4-amd64 join phase --help
Use this command to invoke single phase of the join workflow
Usage:
kubeadm join phase [command]
Available Commands:
control-plane-join Join a machine as a control plane instance
control-plane-prepare Prepare the machine for serving a control plane
kubelet-start Write kubelet settings, certificates and (re)start the kubelet
preflight Run join pre-flight checks
wait-control-plane EXPERIMENTAL: Wait for the control plane to start
操作流程 preflight → control-plane-prepare → kubelet-start → control-plane-join → wait-control-plan
# 查看token
root@node1:/tmp/releases# ./kubeadm-v1.31.4-amd64 token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
7y9wsq.m39141nuiqbqp3jf 23h 2025-06-24T05:05:26Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
8dmx1v.y68sd65fizm097h7 1h 2025-06-23T07:05:20Z <none> Proxy for managing TTL for the kubeadm-certs secret <none>
a8yy39.u0tvtbzypg0inqp7 23h 2025-06-24T05:05:25Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
b7qg4l.y2nw6n63lz7zv4ii 23h 2025-06-24T05:05:25Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
di7ppa.7nla9o35v1otkrr6 1h 2025-06-23T07:05:27Z <none> Proxy for managing TTL for the kubeadm-certs secret <none>
iswh4x.rao77z1q88ucwaco 23h 2025-06-24T05:05:20Z authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
kubespray 使用
- files_repo: “https://files.m.daocloud.io”
- gcr_image_repo: “gcr.m.daocloud.io”
- kube_image_repo: “k8s-gcr.m.daocloud.io”
- docker_image_repo: “docker.m.daocloud.io”
- quay_image_repo: “quay.m.daocloud.io”
- github_image_repo: “ghcr.m.daocloud.io”
inventory 配置
配置项:
- kube_control_plane
- etcd
- kube_node节点
额外
- 堡垒机 bastion
指定网络信息
# inventory/mycluster/group_vars/k8s_cluster/k8s-cluster.yml
# 这里使用 calico
kube_network_plugin: calico
# service 网络段
kube_service_addresses: 10.233.0.0/18
# pod 网络段
kube_pods_subnet: 10.233.64.0/18
安装完 venv 后
# 进入虚拟环境
root@node1:/opt/kubespray# source kubespray-venv/bin/activate
# 安装新集群
(kubespray-venv) root@node1:/opt/kubespray# ansible-playbook -i inventory/mycluster/inventory.ini cluster.yml -b -v
`
# 扩容
(kubespray-venv) root@node1:/opt/kubespray# ansible-playbook -i inventory/mycluster/inventory.ini scale.yml --verbose