Controller
控制器
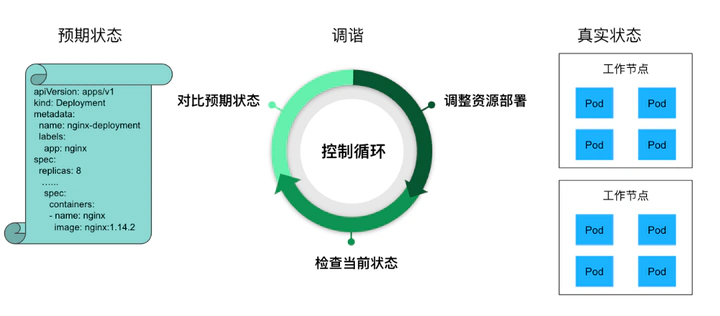
控制循环就是一个用来调节系统状态的周期性操作,在 Kubernetes 中也叫调谐循环(Reconcile Loop)。我的手下控制着很多种不同类型的资源,比如 Pod,Deployment,Service 等等。就拿 Deployment 来说吧,我的控制循环主要分为三步:
从 API Server 中获取到所有属于该 Deployment 的 Pod,然后统计一下它们的数量,即它们的实际状态。
检查 Deployment 的 Replicas 字段,看看期望状态是多少个 Pod。
将这两个状态做比较,如果期望状态的 Pod 数量比实际状态多,就创建新 Pod,多几个就创建几个新的;如果期望状态的 Pod 数量比实际状态少,就删除旧 Pod,少几个就删除几个旧的。
控制器进化之旅
第一阶段:控制器直接访问api-server

过多的请求,导致api-server压力过大
第二阶段:控制器通过informer访问api-server

- informer提供的List And Watch机制,增量的请求api-server
- watch时,只watch特定的资源
多个控制器共享informer访问api-server

针对每个(受多个控制器管理的)资源招一个 Informer 小弟.SharedInformer 无法同时给多个控制器提供信息,这就需要每个控制器自己排队和重试。
为了配合控制器更好地实现排队和重试,SharedInformer 搞了一个 Delta FIFO Queue(增量先进先出队列),每当资源被修改时,它的助手 Reflector 就会收到事件通知,并将对应的事件放入 Delta FIFO Queue 中。与此同时,SharedInformer 会不断从 Delta FIFO Queue 中读取事件,然后更新本地缓存的状态。
这还不行,SharedInformer 除了更新本地缓存之外,还要想办法将数据同步给各个控制器,为了解决这个问题,它又搞了个工作队列(Workqueue),一旦有资源被添加、修改或删除,就会将相应的事件加入到工作队列中。所有的控制器排队进行读取,一旦某个控制器发现这个事件与自己相关,就执行相应的操作。如果操作失败,就将该事件放回队列,等下次排到自己再试一次。如果操作成功,就将该事件从队列中删除。
- 受多个控制器管理的资源对象,共享Informer,进一步提高效率。比如:Deployment和DaemonSet两个控制器都管理pod资源
- DeltaFIFO队列用于处理事件通知,并更新本地缓存
- WorkQueue队列用于通知各个控制器处理事件
第四阶段:自定义控制器+自定义资源访问 api-server

Open Application Model(OAM)

Open Application Model 。这个模型就是为了解决上面提到的问题,将开发和运维的职责解耦,不同的角色履行不同的职责,并形成一个统一的规范,如下图所示
内置的控制器
// https://github.com/kubernetes/kubernetes/blob/27e23bad7d595f64519de70f1a82539d14327a28/cmd/kube-controller-manager/app/controllermanager.go
func NewControllerInitializers(loopMode ControllerLoopMode) map[string]InitFunc {
controllers := map[string]InitFunc{}
// All of the controllers must have unique names, or else we will explode.
register := func(name string, fn InitFunc) {
if _, found := controllers[name]; found {
panic(fmt.Sprintf("controller name %q was registered twice", name))
}
controllers[name] = fn
}
register("endpoint", startEndpointController)
register("endpointslice", startEndpointSliceController)
register("endpointslicemirroring", startEndpointSliceMirroringController)
register("replicationcontroller", startReplicationController)
register("podgc", startPodGCController)
register("resourcequota", startResourceQuotaController)
register("namespace", startNamespaceController)
register("serviceaccount", startServiceAccountController)
register("garbagecollector", startGarbageCollectorController)
register("daemonset", startDaemonSetController)
register("job", startJobController)
register("deployment", startDeploymentController)
register("replicaset", startReplicaSetController)
register("horizontalpodautoscaling", startHPAController)
register("disruption", startDisruptionController)
register("statefulset", startStatefulSetController)
register("cronjob", startCronJobController)
register("csrsigning", startCSRSigningController)
register("csrapproving", startCSRApprovingController)
register("csrcleaner", startCSRCleanerController)
register("ttl", startTTLController)
register("bootstrapsigner", startBootstrapSignerController)
register("tokencleaner", startTokenCleanerController)
register("nodeipam", startNodeIpamController)
register("nodelifecycle", startNodeLifecycleController)
if loopMode == IncludeCloudLoops {
register("service", startServiceController)
register("route", startRouteController)
register("cloud-node-lifecycle", startCloudNodeLifecycleController)
// TODO: volume controller into the IncludeCloudLoops only set.
}
register("persistentvolume-binder", startPersistentVolumeBinderController)
register("attachdetach", startAttachDetachController)
register("persistentvolume-expander", startVolumeExpandController)
register("clusterrole-aggregation", startClusterRoleAggregrationController)
register("pvc-protection", startPVCProtectionController)
register("pv-protection", startPVProtectionController)
register("ttl-after-finished", startTTLAfterFinishedController)
register("root-ca-cert-publisher", startRootCACertPublisher)
register("ephemeral-volume", startEphemeralVolumeController)
if utilfeature.DefaultFeatureGate.Enabled(genericfeatures.APIServerIdentity) &&
utilfeature.DefaultFeatureGate.Enabled(genericfeatures.StorageVersionAPI) {
register("storage-version-gc", startStorageVersionGCController)
}
if utilfeature.DefaultFeatureGate.Enabled(kubefeatures.DynamicResourceAllocation) {
register("resource-claim-controller", startResourceClaimController)
}
return controllers
}
案例-ReplicaSetController
额外说明: 新版本的 Kubernetes 中建议使用 ReplicaSet(简称为RS )来取代 Replication Controller(RC)
// It is actually just a wrapper around ReplicaSetController.
type ReplicationManager struct {
replicaset.ReplicaSetController
}
主要逻辑
// https://github.com/kubernetes/kubernetes/blob/8f45b64c93563ef682f24d1f6300679d03d946f1/pkg/controller/replicaset/replica_set.go
func (rsc *ReplicaSetController) syncReplicaSet(ctx context.Context, key string) error {
startTime := time.Now()
defer func() {
klog.FromContext(ctx).V(4).Info("Finished syncing", "kind", rsc.Kind, "key", key, "duration", time.Since(startTime))
}()
// 从 key 获取 namespace 命令空间 和 name 集合名.
namespace, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
return err
}
// 获取 rs 实例对象
rs, err := rsc.rsLister.ReplicaSets(namespace).Get(name)
if apierrors.IsNotFound(err) {
// 如果 rs 已经被删除,则尝试在 expectations 清空对应的记录.
klog.FromContext(ctx).V(4).Info("deleted", "kind", rsc.Kind, "key", key)
rsc.expectations.DeleteExpectations(key)
return nil
}
if err != nil {
return err
}
// 检查期望是否达成
rsNeedsSync := rsc.expectations.SatisfiedExpectations(key)
selector, err := metav1.LabelSelectorAsSelector(rs.Spec.Selector)
if err != nil {
utilruntime.HandleError(fmt.Errorf("error converting pod selector to selector for rs %v/%v: %v", namespace, name, err))
return nil
}
// 获取 rs 所在命名空间下的所有 pod
allPods, err := rsc.podLister.Pods(rs.Namespace).List(labels.Everything())
if err != nil {
return err
}
// 排除掉 terminated 状态下的 pod
filteredPods := controller.FilterActivePods(allPods)
// 遍历每个 pod ,如果有 rs 控制,则根据 uis 判断 rs 是否是控制自己的 rs
// 如果 pod 的 rs 被删除,或者 pod 被释放,或者 2者 同时发生,则过滤掉这些 pod
// 如果 pod 标签跟当前的 rs 匹配,则尝试给 pod 配置上 对应的 OwnerReferences,如果 pod 已经有其他的 OwnerReferences,则收养失败,会把 pod 过滤掉
filteredPods, err = rsc.claimPods(ctx, rs, selector, filteredPods)
if err != nil {
return err
}
var manageReplicasErr error
if rsNeedsSync && rs.DeletionTimestamp == nil {
// 同步 rs
manageReplicasErr = rsc.manageReplicas(ctx, filteredPods, rs)
}
// 更新 rs status 字段
rs = rs.DeepCopy()
newStatus := calculateStatus(rs, filteredPods, manageReplicasErr)
// 通过 clientset 更新 rs 的状态,并将更新完状态的 rs 对象返回
updatedRS, err := updateReplicaSetStatus(klog.FromContext(ctx), rsc.kubeClient.AppsV1().ReplicaSets(rs.Namespace), rs, newStatus)
if err != nil {
// Multiple things could lead to this update failing. Requeuing the replica set ensures
// Returning an error causes a requeue without forcing a hotloop
return err
}
// Resync the ReplicaSet after MinReadySeconds as a last line of defense to guard against clock-skew.
if manageReplicasErr == nil && updatedRS.Spec.MinReadySeconds > 0 &&
updatedRS.Status.ReadyReplicas == *(updatedRS.Spec.Replicas) &&
updatedRS.Status.AvailableReplicas != *(updatedRS.Spec.Replicas) {
rsc.queue.AddAfter(key, time.Duration(updatedRS.Spec.MinReadySeconds)*time.Second)
}
return manageReplicasErr
}
判断是否需要同步 SatisfiedExpectations
func (r *ControllerExpectations) SatisfiedExpectations(controllerKey string) bool {
if exp, exists, err := r.GetExpectations(controllerKey); exists { // 如果有 exp 对象, 那么判断是否满足条件或者超过同步周期, 则返回 true
if exp.Fulfilled() {
klog.V(4).Infof("Controller expectations fulfilled %#v", exp)
return true
} else if exp.isExpired() {
klog.V(4).Infof("Controller expectations expired %#v", exp)
return true
} else {
klog.V(4).Infof("Controller still waiting on expectations %#v", exp)
return false
}
} else if err != nil {
klog.V(2).Infof("Error encountered while checking expectations %#v, forcing sync", err)
} else {
// When a new controller is created, it doesn't have expectations.
// When it doesn't see expected watch events for > TTL, the expectations expire.
// - In this case it wakes up, creates/deletes controllees, and sets expectations again.
// When it has satisfied expectations and no controllees need to be created/destroyed > TTL, the expectations expire.
// - In this case it continues without setting expectations till it needs to create/delete controllees.
klog.V(4).Infof("Controller %v either never recorded expectations, or the ttl expired.", controllerKey)
}
// Trigger a sync if we either encountered and error (which shouldn't happen since we're
// getting from local store) or this controller hasn't established expectations.
return true
}
管理 ReplicaSet pod 个数
func (rsc *ReplicaSetController) manageReplicas(ctx context.Context, filteredPods []*v1.Pod, rs *apps.ReplicaSet) error {
// 查看 rs 的 pod 个数
diff := len(filteredPods) - int(*(rs.Spec.Replicas))
rsKey, err := controller.KeyFunc(rs)
if err != nil {
utilruntime.HandleError(fmt.Errorf("couldn't get key for %v %#v: %v", rsc.Kind, rs, err))
return nil
}
if diff < 0 { // 少补
diff *= -1
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
// TODO: Track UIDs of creates just like deletes. The problem currently
// is we'd need to wait on the result of a create to record the pod's
// UID, which would require locking *across* the create, which will turn
// into a performance bottleneck. We should generate a UID for the pod
// beforehand and store it via ExpectCreations.
rsc.expectations.ExpectCreations(rsKey, diff)
klog.FromContext(ctx).V(2).Info("Too few replicas", "replicaSet", klog.KObj(rs), "need", *(rs.Spec.Replicas), "creating", diff)
// 批量创建 pod ,个数 1、2、4、8 以此类推
successfulCreations, err := slowStartBatch(diff, controller.SlowStartInitialBatchSize, func() error {
err := rsc.podControl.CreatePods(ctx, rs.Namespace, &rs.Spec.Template, rs, metav1.NewControllerRef(rs, rsc.GroupVersionKind))
if err != nil {
if apierrors.HasStatusCause(err, v1.NamespaceTerminatingCause) {
// if the namespace is being terminated, we don't have to do
// anything because any creation will fail
return nil
}
}
return err
})
// Any skipped pods that we never attempted to start shouldn't be expected.
// The skipped pods will be retried later. The next controller resync will
// retry the slow start process.
if skippedPods := diff - successfulCreations; skippedPods > 0 {
klog.FromContext(ctx).V(2).Info("Slow-start failure. Skipping creation of pods, decrementing expectations", "podsSkipped", skippedPods, "kind", rsc.Kind, "replicaSet", klog.KObj(rs))
for i := 0; i < skippedPods; i++ {
// Decrement the expected number of creates because the informer won't observe this pod
rsc.expectations.CreationObserved(rsKey)
}
}
return err
} else if diff > 0 { // 多删
if diff > rsc.burstReplicas {
diff = rsc.burstReplicas
}
klog.FromContext(ctx).V(2).Info("Too many replicas", "replicaSet", klog.KObj(rs), "need", *(rs.Spec.Replicas), "deleting", diff)
relatedPods, err := rsc.getIndirectlyRelatedPods(klog.FromContext(ctx), rs)
utilruntime.HandleError(err)
// Choose which Pods to delete, preferring those in earlier phases of startup.
podsToDelete := getPodsToDelete(filteredPods, relatedPods, diff)
// Snapshot the UIDs (ns/name) of the pods we're expecting to see
// deleted, so we know to record their expectations exactly once either
// when we see it as an update of the deletion timestamp, or as a delete.
// Note that if the labels on a pod/rs change in a way that the pod gets
// orphaned, the rs will only wake up after the expectations have
// expired even if other pods are deleted.
rsc.expectations.ExpectDeletions(rsKey, getPodKeys(podsToDelete))
errCh := make(chan error, diff)
var wg sync.WaitGroup
wg.Add(diff)
for _, pod := range podsToDelete {
go func(targetPod *v1.Pod) {
defer wg.Done()
if err := rsc.podControl.DeletePod(ctx, rs.Namespace, targetPod.Name, rs); err != nil {
// Decrement the expected number of deletes because the informer won't observe this deletion
podKey := controller.PodKey(targetPod)
rsc.expectations.DeletionObserved(rsKey, podKey)
if !apierrors.IsNotFound(err) {
klog.FromContext(ctx).V(2).Info("Failed to delete pod, decremented expectations", "pod", podKey, "kind", rsc.Kind, "replicaSet", klog.KObj(rs))
errCh <- err
}
}
}(pod)
}
wg.Wait()
select {
case err := <-errCh:
// all errors have been reported before and they're likely to be the same, so we'll only return the first one we hit.
if err != nil {
return err
}
default:
}
}
return nil
}
exceptions 预期集合
什么作用 ? expectations 会记录 rs 所有对象需要 add/del 的 pod 数量.
若两者都为 0 则说明该 rs 所期望创建的 pod 或者删除的 pod 数已经被满足,若不满足则说明某次在 syncLoop 中创建或者删除 pod 时有失败的操作,则需要等待 expectations 过期后再次同步该 rs.