Gpu Scheduler
背景
- 随着 AI 热度越来越高,更多的业务 Pod 需要申请 GPU 资源
基本概念
异构计算(Heterogeneous Computing)
异构,就是CPU、DSP、GPU、ASIC、协处理器、FPGA等各种计算单元、使用不同的类型指令集、不同的体系架构的计算单元,组成一个混合的系统,执行计算的特殊方式,就叫做“异构计算”。
异构计算(Heterogeneous Computing),主要指不同类型的指令集和体系架构的计算单元组成的系统的计算方式。
异构计算平台就是“CPU+GPU”以及“CPU+FPGA” 架构。这些典型异构计算架构最大的优点是具有比传统CPU并行计算更高效率和低延迟的计算性能.
CUDA
在 2006 年,英伟达和 ATI 分别推出了 CUDA(Compute Unified Device Architecture)和 CTM(CLOSE TO THE METAL)编程环境。
这一举措打破了 GPU 仅限于图形语言的局限,将 GPU 变成了真正的并行数据处理超级加速器。 CUDA 和 CTM 的推出使得开发者可以更灵活地利用 GPU 的计算能力,为科学计算、数据分析等领域提供了更多可能性。
2008 年,苹果公司推出了一个通用的并行计算编程平台 OPENCL(Open Computing Language)。与 CUDA 不同,OPENCL 并不与特定的硬件绑定,而是与具体的计算设备无关,这使得它迅速成为移动端 GPU 的编程环境业界标准。

在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)
CUDA(Compute Unified Device Architecture)的软件堆栈由驱动层、运行时层和函数库层构成。
CUDA软件堆栈中的驱动层API和运行时层API的区别如下
驱动层API(Driver API):功能较完整,但是使用复杂。
运行时API(CUDA Runtime API):封装了部分驱动的API,将某些驱动初始化操作隐藏,使用方便.
典型的CUDA程序的执行流程如下:
- 分配host内存,并进行数据初始化;
- 分配device内存,并从host将数据拷贝到device上;
- 调用CUDA的核函数在device上完成指定的运算;
- 将device上的运算结果拷贝到host上;
- 释放device和host上分配的内存。

kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。
CUDA的内存模型

CPU 对比 GPU

CPU(Central Processing Unit)是一块超大规模的集成电路,是一台计算机的运算核心(Core)和控制核心( Control Unit)。它的功能主要是解释计算机指令以及处理计算机软件中的数据
CPU主要包括运算器(算术逻辑运算单元,ALU,Arithmetic Logic Unit)、控制单元(CU, Control Unit)、寄存器(Register)、和高速缓冲存储器(Cache)及实现它们之间联系的数据(Data)、控制及状态的总线(Bus)。 简单来说就是:计算单元、控制单元和存储单元。CPU遵循的是冯诺依曼架构,其核心就是:存储程序,顺序执行。
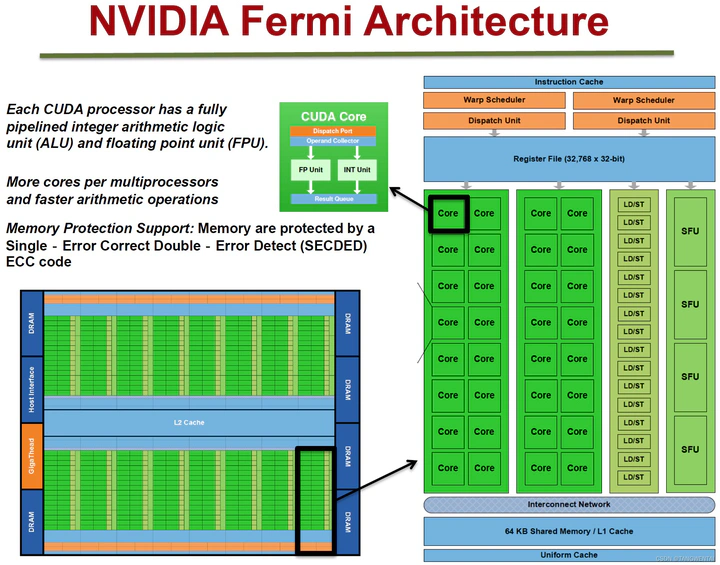
GPU (Graphics Processing Unit)这个概念由NVIDIA公司于1999年提出。GPU是显卡上的一块芯片,就像CPU是主板上的一块芯片. GPU采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了Cache。
使用
对于裸机环境,只需要安装对应的 GPU Driver 以及 CUDA Toolkit 。
对应 Docker 环境,需要额外安装 nvidia-container-toolkit 并配置 docker 使用 nvidia runtime。
$ cat /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}
$ docker run --rm -it --gpus all tensorflow/tensorflow:2.6.0-gpu bash
- 对应 k8s 环境,需要额外安装对应的 device-plugin 使得 kubelet 能够感知到节点上的 GPU 设备,以便 k8s 能够进行 GPU 管理
$ cat /etc/containerd/config.toml
[plugins."io.containerd.grpc.v1.cri".containerd]
default_runtime_name = "runc"
snapshotter = "overlayfs"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
runtime_engine = ""
runtime_root = ""
runtime_type = "io.containerd.runc.v2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
SystemdCgroup = true
$ kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.14.3/nvidia-device-plugin.yml
Device Plugin
在 k8s 环境中使用 GPU,就是靠 Device Plugin 机制,通过该机制使得 k8s 能感知到节点上的 GPU 资源,就像原生的 CPU 和 Memory 资源一样使用
在 1.8 版本引入了 device plugin 机制,通过插件形式来接入其他资源,设备厂家只需要开发对应的 xxx-device-plugin 就可以将资源接入到 k8s 了。
比如 NVIDIA 的device plugin: https://github.com/NVIDIA/k8s-device-plugin/tree/v0.16.2
Device Plugin 原理
Device Plugin 的工作原理其实不复杂,可以分为 插件注册 和 kubelet 调用插件两部分。
- 插件注册:DevicePlugin 启动时会向节点上的 Kubelet 发起注册,这样 Kubelet就可以感知到该插件的存在了
- kubelet 调用插件:注册完成后,当有 Pod 申请对于资源时,kubelet 就会调用该插件 API 实现具体功能
service Registration {
rpc Register(RegisterRequest) returns (Empty) {}
}
message RegisterRequest {
// Version of the API the Device Plugin was built against
string version = 1;
// Name of the unix socket the device plugin is listening on
// PATH = path.Join(DevicePluginPath, endpoint)
string endpoint = 2;
// Schedulable resource name. As of now it's expected to be a DNS Label
string resource_name = 3;
// Options to be communicated with Device Manager
DevicePluginOptions options = 4;
}
device plugin 可以调用该接口向 Kubelet 进行注册,注册接口需要提供三个参数:
device plugin 对应的 unix socket 名字:后续 kubelet 根据名称找到对应的 unix socket,并向插件发起调用
device plugin 调 API version:用于区分不同版本的插件
device plugin 提供的 ResourceName:遇到不能处理的资源申请时(CPU和Memory之外的资源),Kubelet 就会根据申请的资源名称来匹配对应的插件
ResourceName 需要按照vendor-domain/resourcetype 格式,例如nvidia.com/gpu
// DevicePlugin is the service advertised by Device Plugins
service DevicePlugin {
// GetDevicePluginOptions returns options to be communicated with Device
// Manager
rpc GetDevicePluginOptions(Empty) returns (DevicePluginOptions) {}
// ListAndWatch returns a stream of List of Devices
// Whenever a Device state change or a Device disappears, ListAndWatch
// returns the new list
rpc ListAndWatch(Empty) returns (stream ListAndWatchResponse) {}
// GetPreferredAllocation returns a preferred set of devices to allocate
// from a list of available ones. The resulting preferred allocation is not
// guaranteed to be the allocation ultimately performed by the
// devicemanager. It is only designed to help the devicemanager make a more
// informed allocation decision when possible.
rpc GetPreferredAllocation(PreferredAllocationRequest) returns (PreferredAllocationResponse) {}
// Allocate is called during container creation so that the Device
// Plugin can run device specific operations and instruct Kubelet
// of the steps to make the Device available in the container
rpc Allocate(AllocateRequest) returns (AllocateResponse) {}
// PreStartContainer is called, if indicated by Device Plugin during registeration phase,
// before each container start. Device plugin can run device specific operations
// such as resetting the device before making devices available to the container
rpc PreStartContainer(PreStartContainerRequest) returns (PreStartContainerResponse) {}
}
device plugin 插件需要实现以下接口:
GetDevicePluginOptions:这个接口用于获取设备插件的信息,可以在其返回的响应中指定一些设备插件的配置选项,可以看做是插件的元数据
ListAndWatch:该接口用于列出可用的设备并持续监视这些设备的状态变化。
GetPreferredAllocation:将分配偏好信息提供给 device plugin,以便 device plugin 在分配时可以做出更好的选择
Allocate:该接口用于向设备插件请求分配指定数量的设备资源。
PreStartContainer: 该接口在容器启动之前调用,用于配置容器使用的设备资源
kubelet 注册 device plugin
注册
// https://github.com/kubernetes/kubernetes/blob/40741681a24a5acf9361ec74b97e887a9da3e3e4/pkg/kubelet/cm/devicemanager/plugin/v1beta1/server.go
func (s *server) Register(ctx context.Context, r *api.RegisterRequest) (*api.Empty, error) {
klog.InfoS("Got registration request from device plugin with resource", "resourceName", r.ResourceName)
if !s.isVersionCompatibleWithPlugin(r.Version) {
// ..
}
if !v1helper.IsExtendedResourceName(core.ResourceName(r.ResourceName)) {
// ..
}
// 连接客户端
if err := s.connectClient(r.ResourceName, filepath.Join(s.socketDir, r.Endpoint)); err != nil {
// ..
}
return &api.Empty{}, nil
}
func (s *server) connectClient(name string, socketPath string) error {
c := NewPluginClient(name, socketPath, s.chandler)
s.registerClient(name, c)
if err := c.Connect(); err != nil {
s.deregisterClient(name)
klog.ErrorS(err, "Failed to connect to new client", "resource", name)
return err
}
go func() {
s.runClient(name, c)
}()
return nil
}
func (s *server) runClient(name string, c Client) {
c.Run()
c = s.getClient(name)
if c == nil {
return
}
if err := s.disconnectClient(name, c); err != nil {
klog.V(2).InfoS("Unable to disconnect client", "resource", name, "client", c, "err", err)
}
}
// https://github.com/kubernetes/kubernetes/blob/25dc4c4f320ecb75b936220c1c66741bce4b9014/pkg/kubelet/cm/devicemanager/plugin/v1beta1/client.go
func (c *client) Run() {
// 调用list-watch 资源的最新信息
stream, err := c.client.ListAndWatch(context.Background(), &api.Empty{})
if err != nil {
klog.ErrorS(err, "ListAndWatch ended unexpectedly for device plugin", "resource", c.resource)
return
}
for {
response, err := stream.Recv()
if err != nil {
klog.ErrorS(err, "ListAndWatch ended unexpectedly for device plugin", "resource", c.resource)
return
}
klog.V(2).InfoS("State pushed for device plugin", "resource", c.resource, "resourceCapacity", len(response.Devices))
c.handler.PluginListAndWatchReceiver(c.resource, response)
}
}
kubelet 请求分配资源
// https://github.com/kubernetes/kubernetes/blob/e5512149e209453fe24b666c8a48fbc4dc96f05b/pkg/kubelet/cm/devicemanager/manager.go
func (m *ManagerImpl) allocateContainerResources(pod *v1.Pod, container *v1.Container, devicesToReuse map[string]sets.String) error {
podUID := string(pod.UID)
contName := container.Name
allocatedDevicesUpdated := false
needsUpdateCheckpoint := false
// Extended resources are not allowed to be overcommitted.
// Since device plugin advertises extended resources,
// therefore Requests must be equal to Limits and iterating
// over the Limits should be sufficient.
for k, v := range container.Resources.Limits {
resource := string(k)
needed := int(v.Value())
// ...
// 需要分配的设备
allocDevices, err := m.devicesToAllocate(podUID, contName, resource, needed, devicesToReuse[resource])
// ...
// 打乱顺序
devs := allocDevices.UnsortedList()
// 分配资源
resp, err := eI.e.allocate(devs)
// ...
allocDevicesWithNUMA := checkpoint.NewDevicesPerNUMA()
// Update internal cached podDevices state.
m.mutex.Lock()
for dev := range allocDevices {
if m.allDevices[resource][dev].Topology == nil || len(m.allDevices[resource][dev].Topology.Nodes) == 0 {
allocDevicesWithNUMA[nodeWithoutTopology] = append(allocDevicesWithNUMA[nodeWithoutTopology], dev)
continue
}
for idx := range m.allDevices[resource][dev].Topology.Nodes {
node := m.allDevices[resource][dev].Topology.Nodes[idx]
allocDevicesWithNUMA[node.ID] = append(allocDevicesWithNUMA[node.ID], dev)
}
}
m.mutex.Unlock()
m.podDevices.insert(podUID, contName, resource, allocDevicesWithNUMA, resp.ContainerResponses[0])
}
if needsUpdateCheckpoint {
return m.writeCheckpoint()
}
return nil
}
func (e *endpointImpl) allocate(devs []string) (*pluginapi.AllocateResponse, error) {
// ...
// 调用 Allocate
return e.api.Allocate(context.Background(), &pluginapi.AllocateRequest{
ContainerRequests: []*pluginapi.ContainerAllocateRequest{
{DevicesIDs: devs},
},
})
}
基于 K8S 的 GPU 虚拟化框架
GPU 虚拟化,除了 GPU 厂商能够在硬件和驱动层面对各种资源进行划分进而形成隔离的虚拟化方案之外,
GPU共享资源隔离方案
- gpu share。阿里GPU Share Device Plugin。不支持共享资源的隔离
- 截获CUDA库转发,如vCUDA。
- 截获驱动转发,如阿里云cGPU、腾讯云qGPU。

- 截获GPU硬件访问,如NVIDIA GRID vGPU.
vGPU
vGPU 的优势
- vGPU 允许每个 VM 拥有 GPU 资源的专用部分。这确保了每个 VM 的一致且可预测的性能。
- 由于资源是静态分配的,因此在一个 VM 中运行的工作负载不会干扰另一个 VM 中的工作负载,从而防止由于资源争用而导致的性能下降。
- 每个 vGPU 实例都在其自己的 VM 中运行,提供了强大的安全边界。这种隔离对于多租户环境至关重要,在这些环境中,数据隐私和安全性至关重要,并且在高度监管的行业中通常是强制性的。
- 一个 vGPU 实例中的错误或故障将被限制在该实例内,防止它们影响共享同一个物理 GPU 的其他 VM。
- 虽然最大分区数量取决于 GPU 实例模型和 vGPU 管理器软件,但 vGPU 支持创建每个 GPU 最多 20 个分区,使用 A100 80GB GPU 和NVIDIA 虚拟计算服务器 (vCS)。
Multi-Instance GPU (MIG)
一颗 Discrete GPU 的硬件资源主要包括两类:计算单元和内部存储
它允许将单个物理 GPU 在硬件级别划分为多个隔离的 GPU 实例。 每个实例独立运行,拥有自己的专用计算、内存和带宽资源。这使多个用户或应用程序能够共享单个 GPU,同时保持性能隔离和安全性。
MIG 的优势
- MIG 确保 GPU 资源得到充分利用,减少空闲时间并提高整体效率。
- MIG 将 GPU 静态分区为多个隔离的实例,每个实例都有自己的专用资源部分,包括SM(Streaming Multiprocessors,流式多处理器);确保更好且可预测的流式多处理器 (SM)服务质量 (QoS)。
- 专用部分内存在多个隔离的实例中确保更好的内存 QoS。
- 静态分区还提供错误隔离,从而实现故障隔离和系统稳定性。
- 更好的数据保护和恶意活动的隔离,为多租户设置提供更好的安全性。
Time-Sliced vGPU 时间切片

GPU 时间切片是一种虚拟化技术,允许多个工作负载或虚拟机 (VM) 通过将处理时间划分为离散切片来共享单个 GPU。 每个切片按顺序将 GPU 的计算和内存资源的一部分分配给不同的任务或用户。 这使得能够在单个 GPU 上并发执行多个任务,最大限度地提高资源利用率并确保公平地将 GPU 时间分配给每个工作负载
GPU 时间切片的优势
- 最大限度地提高资源利用率并减少空闲时间,无需专门的硬件或专有软件。
- 减少对额外硬件的需求,从而降低运营成本。
- 提供灵活性,根据工作负载需求处理不同的计算需求。
- 时间切片相对易于实施和管理,使其适用于不需要复杂资源管理的环境。
- 此方法对于可以容忍 GPU 访问和性能变化的非关键任务有效,例如后台处理或批处理作业。
- 可用最大分区数量不受限制。
volcano GPU 虚拟化
https://volcano.sh/zh/docs/v1-12-0/gpu_virtualization/
Volcano主要支持以下两种GPU共享模式
1 HAMI-core(基于软件的vGPU)
描述: 通过 VCUDA (一种CUDA API劫持技术) 对GPU核心与显存的使用进行限制,从而实现软件层面的虚拟GPU切片。
使用场景: 适用于需要细粒度GPU共享的场景,兼容所有类型的GPU。
2 Dynamic MIG(硬件级GPU切片)
描述: 采用NVIDIA的MIG (Multi-Instance GPU)技术,可将单个物理GPU分割为多个具备硬件级性能保障的隔离实例。
使用场景: 尤其适用于对性能敏感的工作负载,要求GPU支持MIG特性(如A100、H100系列)。
容器侧:CUDA 工具集

工具: github.com/NVIDIA/nvidia-container-toolkit
一个典型的 GPU 应用软件栈如下图所示。
- 其中,最上层的是多个包含了业务应用在内的容器。每个容器都分别包含了业务应用、CUDA 工具集(CUDA Toolkit)和容器 RootFS;
- 中间层是容器引擎(docker)和安装了 CUDA 驱动程序的宿主机操作系统;
- 最底层是部署了多个 GPU 硬件显卡的服务器硬件。
如何利用容器运行GPU程序
- 直接使用深度学习的容器镜像 tensorflow : https://github.com/tensorflow/tensorflow/blob/v2.17.0/tensorflow/tools/ci_build/Dockerfile.gpu
- 基于cuda镜像基础构建