Volcano
Volcano 主要用于AI、大数据、基因、渲染等诸多高性能计算场景,对主流通用计算框架均有很好的支持。 它提供高性能计算任务调度,异构设备管理,任务运行时管理等能力.
基本概念
cpu 相关
# 有2个socket,每个socket有10个核,每个核开超线程,总共2*10*2=40个逻辑处理器。每个socket划分到一个numa node,总共两个numa。
# lscpu 查看 cpu 拓扑
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 40
On-line CPU(s) list: 0-39
Thread(s) per core: 2
Core(s) per socket: 10
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 79
Model name: Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
Stepping: 1
CPU MHz: 2200.134
CPU max MHz: 2200.0000
CPU min MHz: 1200.0000
BogoMIPS: 4389.32
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 25600K
NUMA node0 CPU(s): 0-9,20-29
NUMA node1 CPU(s): 10-19,30-39
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc aperfmperf eagerfpu pni pclmulqdq dtes64 monitor ds_cpl vmx smx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid dca sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand lahf_lm abm 3dnowprefetch epb cat_l3 cdp_l3 intel_ppin intel_pt ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 hle avx2 smep bmi2 erms invpcid rtm cqm rdt_a rdseed adx smap xsaveopt cqm_llc cqm_occup_llc cqm_mbm_total cqm_mbm_local dtherm arat pln pts spec_ctrl intel_stibp flush_l1d
- Socket(s):主板上面的物理 CPU 插槽。
- Core(s):Core就是平时说的核,双核、四核等,就是每个CPU上的核数
- Thread(s):一个 core 包含多个可以并行处理任务的 thread,即 Thread(s) per core, thread 是单个独立的执行上下文,竞争 core 内寄存器等共享资源。也称为Siblings Thread(兄弟线程),即由同一个 Core 超线程出来的 Threads。
- NUMA nodes:一个 socket 可以划分为多个 NUMA node。Numa使用node来管理CPU和内存。 对操作系统来说,其逻辑CPU的数量就是SocketCoreThread
为什么使用volcano
- k8s原生的调度器仅支持顺序调度容器,即在需要多个容器配合的任务中,顺序调度容易造成容器死锁,更不用提其他的高级调度场景。kube-scheduler是以pod为单位来进行调度的,除了通过亲和性来做一些pod之间的关系处理之外,并没有任何pod间的关联机制。举一个例子,在AI等训练的场景,是需要一批pod同时工作的,而且这些pod要么一起调度成功,要么一起调度失败,
- 资源调度、容灾和干扰隔离:调度器需要在选出所有满足现有容器资源的node中挑选最合适的节点;同一应用或者有资源竞争的任务最好不要部署在同一个node中。
- 高级调度场景:Volcano提供了一组不同的调度算法
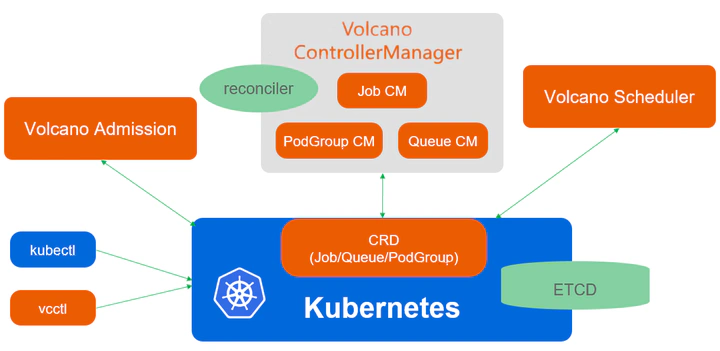
组件
Volcano由scheduler、controllermanager、admission和vcctl组成
- scheduler 通过一系列的action和plugin调度Job,并为它找到一个最适合的节点。与k8s本身的调度器相比,Volcano支持针对Job的多种调度算法。
- controller manager 管理CRD资源的生命周期。对用户创建的batch.volcano.sh/v1alpha1/job以及其他crd资源进行reconcile. 它主要由Queue ControllerManager、PodGroupControllerManager 、 VCJob ControllerManager构成。
- admission负责对CRD API资源进行校验。
- vcctl 是Volcano的命令行客户端工具。
- volcano Agent(可选组件):在节点上收集资源使用情况和硬件信息,为调度器提供更精确的节点资源信息,支持GPU、FPGA等异构资源的管理
Volcano controller
控制器注册
- framework.RegisterController(&gccontroller{})
- framework.RegisterController(&jobcontroller{})
- framework.RegisterController(&jobflowcontroller{})
- framework.RegisterController(&pgcontroller{})
- framework.RegisterController(&queuecontroller{})
- 等等
Queue Controller
主要监听三个资源对象:
- Queue
- PodGroup
- Command
PodGroup Controller
PodGroup Controller比较简单, 它负责为未指定PodGroup的Pod分配PodGroup
func (pg *pgcontroller) processNextReq() bool {
// ...
// 获取pod对象
pod, err := pg.podLister.Pods(req.podNamespace).Get(req.podName)
if err != nil {
klog.Errorf("Failed to get pod by <%v> from cache: %v", req, err)
return true
}
// 根据调度器名称过滤
if !commonutil.Contains(pg.schedulerNames, pod.Spec.SchedulerName) {
klog.V(5).Infof("pod %v/%v field SchedulerName is not matched", pod.Namespace, pod.Name)
return true
}
// 如果pod已经有podgroup, 则不再处理
if pod.Annotations != nil && pod.Annotations[scheduling.KubeGroupNameAnnotationKey] != "" {
klog.V(5).Infof("pod %v/%v has created podgroup", pod.Namespace, pod.Name)
return true
}
// 为pod分配 podgroup
klog.V(4).Infof("Try to create podgroup for pod %s/%s", pod.Namespace, pod.Name)
if err := pg.createNormalPodPGIfNotExist(pod); err != nil {
klog.Errorf("Failed to handle Pod <%s/%s>: %v", pod.Namespace, pod.Name, err)
pg.queue.AddRateLimited(req)
return true
}
// If no error, forget it.
pg.queue.Forget(req)
return true
}
Job Controller
Job是volcano中的核心资源对象, 为了避免与k8s中的Job对象混淆, 也会称之为vcjob或者vj。
Volcano scheduler
scheduler 工作流程
https://volcano.sh/zh/docs/schduler_introduction/
Scheduler是负责Pod调度的组件,它由一系列action和plugin组成。 action定义了调度各环节中需要执行的动作;plugin根据不同场景提供了action 中算法的具体实现细节。 Volcano scheduler具有高度的可扩展性,我们可以根据需要实现自己的action和plugin。

- 当客户端提交的Job后,scheduler就会观察到并缓存起来,即将开启session。
- 开启session,即一个调度周期开始。
- 将没有被调度的Job发送到session的待调度队列中。
- 遍历所有的待调度Job,按照定义的次序依次执行enqueue、allocate、preempt、reclaim、backfill等动作,为每个Job找到一个最合适的节点。将该Job 绑定到这个节点。action中执行的具体算法逻辑取决于注册的plugin中各函数的实现。
- 关闭本次session
cache组件会list/watch, 维护最新的资源信息. 这里拿事件监听 pod add 为例
// https://github.com/volcano-sh/volcano/blob/1693cb0f59841ee21d9fd842516631ebc5b813a1/pkg/scheduler/cache/event_handlers.go
// 新增了一个 pod
func (sc *SchedulerCache) addPod(pod *v1.Pod) error {
// 封装成 task
pi, err := sc.NewTaskInfo(pod)
if err != nil {
klog.Errorf("generate taskInfo for pod(%s) failed: %v", pod.Name, err)
sc.resyncTask(pi)
}
// 写入
return sc.addTask(pi)
}
func (sc *SchedulerCache) addTask(pi *schedulingapi.TaskInfo) error {
if len(pi.NodeName) != 0 {
if _, found := sc.Nodes[pi.NodeName]; !found {
sc.Nodes[pi.NodeName] = schedulingapi.NewNodeInfo(nil)
sc.Nodes[pi.NodeName].Name = pi.NodeName
}
node := sc.Nodes[pi.NodeName]
if !isTerminated(pi.Status) {
if err := node.AddTask(pi); err != nil {
return err
}
} else {
klog.V(4).Infof("Pod <%v/%v> is in status %s.", pi.Namespace, pi.Name, pi.Status.String())
}
}
// 获取或则添加 job
job := sc.getOrCreateJob(pi)
if job != nil {
job.AddTaskInfo(pi)
}
return nil
}
func (sc *SchedulerCache) getOrCreateJob(pi *schedulingapi.TaskInfo) *schedulingapi.JobInfo {
if len(pi.Job) == 0 {
if !slices.Contains(sc.schedulerNames, pi.Pod.Spec.SchedulerName) {
klog.V(4).Infof("Pod %s/%s will not scheduled by %#v, skip creating PodGroup and Job for it",
pi.Pod.Namespace, pi.Pod.Name, sc.schedulerNames)
}
return nil
}
if _, found := sc.Jobs[pi.Job]; !found {
sc.Jobs[pi.Job] = schedulingapi.NewJobInfo(pi.Job)
}
return sc.Jobs[pi.Job]
}
调度开始
// pkg/scheduler/scheduler.go
func (pc *Scheduler) Run(stopCh <-chan struct{}) {
// ...
// 调度器周期性执行逻辑
go wait.Until(pc.runOnce, pc.schedulePeriod, stopCh)
if options.ServerOpts.EnableCacheDumper {
pc.dumper.ListenForSignal(stopCh)
}
go runSchedulerSocket()
}
func (pc *Scheduler) runOnce() {
klog.V(4).Infof("Start scheduling ...")
scheduleStartTime := time.Now()
defer klog.V(4).Infof("End scheduling ...")
pc.mutex.Lock()
actions := pc.actions
plugins := pc.plugins
configurations := pc.configurations
pc.mutex.Unlock()
// Load ConfigMap to check which action is enabled.
conf.EnabledActionMap = make(map[string]bool)
for _, action := range actions {
conf.EnabledActionMap[action.Name()] = true
}
// 打开 session
ssn := framework.OpenSession(pc.cache, plugins, configurations)
defer func() {
framework.CloseSession(ssn)
metrics.UpdateE2eDuration(metrics.Duration(scheduleStartTime))
}()
// 遍历 actions, 执行 action
for _, action := range actions {
actionStartTime := time.Now()
action.Execute(ssn) // 传递了一个 ssn(*Session 类型)对象进去
metrics.UpdateActionDuration(action.Name(), metrics.Duration(actionStartTime))
}
}
session 说明
func OpenSession(cache cache.Cache, tiers []conf.Tier, configurations []conf.Configuration) *Session {
ssn := openSession(cache)
ssn.Tiers = tiers // 存储启用的 tier , 即多层插件
ssn.Configurations = configurations
ssn.NodeMap = GenerateNodeMapAndSlice(ssn.Nodes)
ssn.PodLister = NewPodLister(ssn)
// 遍历 tier
for _, tier := range tiers {
for _, plugin := range tier.Plugins {
if pb, found := GetPluginBuilder(plugin.Name); !found {
klog.Errorf("Failed to get plugin %s.", plugin.Name)
} else {
// 初始化插件
plugin := pb(plugin.Arguments)
// session 注册插件
ssn.plugins[plugin.Name()] = plugin
onSessionOpenStart := time.Now()
plugin.OnSessionOpen(ssn)
metrics.UpdatePluginDuration(plugin.Name(), metrics.OnSessionOpen, metrics.Duration(onSessionOpenStart))
}
}
}
ssn.InitCycleState()
return ssn
}
// 初始化 session 结构体
func openSession(cache cache.Cache) *Session {
ssn := &Session{
UID: uuid.NewUUID(),
// ...
// 用于存储cache中的资源信息, 这些信息是深拷贝的
Jobs: map[api.JobID]*api.JobInfo{},
Nodes: map[string]*api.NodeInfo{},
CSINodesStatus: map[string]*api.CSINodeStatusInfo{},
RevocableNodes: map[string]*api.NodeInfo{},
Queues: map[api.QueueID]*api.QueueInfo{},
plugins: map[string]Plugin{},
jobOrderFns: map[string]api.CompareFn{},
queueOrderFns: map[string]api.CompareFn{},
victimQueueOrderFns: map[string]api.VictimCompareFn{},
taskOrderFns: map[string]api.CompareFn{},
clusterOrderFns: map[string]api.CompareFn{},
predicateFns: map[string]api.PredicateFn{},
prePredicateFns: map[string]api.PrePredicateFn{},
bestNodeFns: map[string]api.BestNodeFn{},
nodeOrderFns: map[string]api.NodeOrderFn{},
batchNodeOrderFns: map[string]api.BatchNodeOrderFn{},
nodeMapFns: map[string]api.NodeMapFn{},
nodeReduceFns: map[string]api.NodeReduceFn{},
hyperNodeOrderFns: map[string]api.HyperNodeOrderFn{},
preemptableFns: map[string]api.EvictableFn{},
reclaimableFns: map[string]api.EvictableFn{},
overusedFns: map[string]api.ValidateFn{},
preemptiveFns: map[string]api.ValidateWithCandidateFn{},
allocatableFns: map[string]api.AllocatableFn{},
jobReadyFns: map[string]api.ValidateFn{},
jobPipelinedFns: map[string]api.VoteFn{},
jobValidFns: map[string]api.ValidateExFn{},
jobEnqueueableFns: map[string]api.VoteFn{},
jobEnqueuedFns: map[string]api.JobEnqueuedFn{},
targetJobFns: map[string]api.TargetJobFn{},
reservedNodesFns: map[string]api.ReservedNodesFn{},
victimTasksFns: map[string][]api.VictimTasksFn{},
jobStarvingFns: map[string]api.ValidateFn{},
simulateRemoveTaskFns: map[string]api.SimulateRemoveTaskFn{},
simulateAddTaskFns: map[string]api.SimulateAddTaskFn{},
simulatePredicateFns: map[string]api.SimulatePredicateFn{},
simulateAllocatableFns: map[string]api.SimulateAllocatableFn{},
}
snapshot := cache.Snapshot()
ssn.Jobs = snapshot.Jobs
for _, job := range ssn.Jobs {
if job.PodGroup != nil {
ssn.PodGroupOldState.Status[job.UID] = *job.PodGroup.Status.DeepCopy()
ssn.PodGroupOldState.Annotations[job.UID] = job.PodGroup.GetAnnotations()
}
}
ssn.NodeList = util.GetNodeList(snapshot.Nodes, snapshot.NodeList)
ssn.HyperNodes = snapshot.HyperNodes
ssn.HyperNodesSetByTier = snapshot.HyperNodesSetByTier
ssn.parseHyperNodesTiers()
ssn.RealNodesList = util.GetRealNodesListByHyperNode(snapshot.RealNodesSet, snapshot.Nodes)
ssn.HyperNodesReadyToSchedule = snapshot.HyperNodesReadyToSchedule
ssn.Nodes = snapshot.Nodes
ssn.CSINodesStatus = snapshot.CSINodesStatus
ssn.RevocableNodes = snapshot.RevocableNodes
ssn.Queues = snapshot.Queues
ssn.NamespaceInfo = snapshot.NamespaceInfo
// calculate all nodes' resource only once in each schedule cycle, other plugins can clone it when need
for _, n := range ssn.Nodes {
ssn.TotalResource.Add(n.Allocatable)
}
klog.V(3).Infof("Open Session %v with <%d> Job and <%d> Queues",
ssn.UID, len(ssn.Jobs), len(ssn.Queues))
return ssn
}
多层级(Tiers)数组结构
tiers:
- plugins: # 第一层插件
- name: priority
- name: gang
- plugins: # 第二层插件
- name: drf
- name: predicates
为什么使用多层级(tiers)数组结构来配置Plugins?
- 优先级分层执行:
- 不同层级(tier)的插件有着严格的优先级顺序
- 高层级(第一个数组)中的插件会先执行,其决策结果会影响或限制低层级插件的决策空间
- 只有当高层级的所有插件都允许一个调度决策时,才会继续执行低层级的插件
- 决策流程的过滤机制:
- 第一层级的插件(如 priority、gang、conformance)主要负责基本的筛选和约束
- 第二层级的插件(如 drf、predicates、proportion 等)负责更细粒度的资源分配和优化
- 这种分层设计形成了一种"粗筛-细筛"的决策流水线
- 解决冲突的明确机制:
- 当不同插件之间可能产生冲突决策时,层级结构提供了明确的优先级规则
- 例如,如果 gang 插件(第一层)决定某个任务不能被调度(因为它的所有成员无法同时运行),那么即使 binpack 插件(第二层)认为该任务可以被有效打包,该任务也不会被调度
plugin
丰富的调度策略
- Gang Scheduling:确保作业的所有任务同时启动,适用于分布式训练、大数据等场景
- Binpack Scheduling:通过任务紧凑分配优化资源利用率
- Heterogeneous device scheduling:高效共享GPU异构资源,支持CUDA和MIG两种模式的GPU调度,支持NPU调度
- Proportion/Capacity Scheduling:基于队列配额进行资源的共享/抢占/回收
- NodeGroup Scheduling:支持节点分组亲和性调度,实现队列与节点组的绑定关系
- DRF(Dominant Resource Fairness) Scheduling:支持多维度资源的公平调度
- SLA Scheduling:基于服务质量的调度保障
- Task-topology Scheduling:支持任务拓扑感知调度,优化通信密集型应用性能
- NUMA Aware Scheduling:支持NUMA架构的调度,优化任务在多核处理器上的资源分配,提升内存访问效率和计算性能
Binpack Scheduling
Binpack 调度算法的目标是尽量把已被占用的节点填满(尽量不往空白节点分配)。
Binpack 在对一个节点打分时,会根据 Binpack 插件自身权重和各资源设置的权重值综合打分。
// https://github.com/volcano-sh/volcano/blob/8944bfd7bc48cb3e1d6b3c047ef2fa52fec4c276/pkg/scheduler/plugins/binpack/binpack.go
func BinPackingScore(task *api.TaskInfo, node *api.NodeInfo, weight priorityWeight) float64 {
score := 0.0
weightSum := 0
requested := task.Resreq
allocatable := node.Allocatable
used := node.Used
for _, resource := range requested.ResourceNames() {
request := requested.Get(resource)
if request == 0 {
continue
}
allocate := allocatable.Get(resource)
nodeUsed := used.Get(resource)
resourceWeight, found := weight.BinPackingResources[resource]
if !found {
continue
}
// 计算得分
resourceScore, err := ResourceBinPackingScore(request, allocate, nodeUsed, resourceWeight)
if err != nil {
klog.V(4).Infof("task %s/%s cannot binpack node %s: resource: %s is %s, need %f, used %f, allocatable %f",
task.Namespace, task.Name, node.Name, resource, err.Error(), request, nodeUsed, allocate)
return 0
}
klog.V(5).Infof("task %s/%s on node %s resource %s, need %f, used %f, allocatable %f, weight %d, score %f",
task.Namespace, task.Name, node.Name, resource, request, nodeUsed, allocate, resourceWeight, resourceScore)
score += resourceScore
weightSum += resourceWeight
}
// mapping the result from [0, weightSum] to [0, 10(MaxPriority)]
if weightSum > 0 {
// 总得分
score /= float64(weightSum)
}
score *= float64(k8sFramework.MaxNodeScore * int64(weight.BinPackingWeight))
return score
}
// 计算公式 Resource.weight * (request + used) / allocatable
func ResourceBinPackingScore(requested, capacity, used float64, weight int) (float64, error) {
if capacity == 0 || weight == 0 {
return 0, nil
}
usedFinally := requested + used
if usedFinally > capacity {
return 0, fmt.Errorf("not enough")
}
score := usedFinally * float64(weight) / capacity
return score, nil
}
这里 cpu 为例
# CPU 权重值越高,得分越高,节点资源使用量越满,得分越高。Memory、GPU 等资源原理类似
CPU.weight * (request + used) / allocatable
- CPU.weight 为用户设置的 CPU 权重
- request 为当前 Pod 请求的 CPU 资源量
- used 为当前节点已经分配使用的 CPU 量
- allocatable 为当前节点 CPU 可用总量
DRF(Dominant Resource Fairness) Scheduling
DRF 调度策略认为占用资源较少的任务具有更高的优先级。这样能够满足更多的作业,不会因为一个胖业务, 饿死大批小业务。 DRF 调度算法能够确保在多种类型资源共存的环境下,尽可能满足分配的公平原则。
NUMA Aware Scheduling
从糟糕的使用方式来看,如果两个进程的CPU内核在分配时,可能会没有遵循NUMA的亲和性,会带来很大的性能问题,体现在三个方面:
CPU争抢带来频繁的上下文切换时间;
频繁的进程切换导致CPU高速缓存失败;
跨NUMA访存会带来更严重的性能瓶颈。
https://github.com/volcano-sh/volcano/blob/master/docs/design/numa-aware.md
https://github.com/volcano-sh/volcano/blob/master/docs/user-guide/how_to_use_numa_aware.md

当CPU不断增长的情况下,共享的系统总线就会因为资源竞争(多核争抢总线资源以访问北桥上的内存)而出现扩展和性能问题,基于SMP架构上的优化,设计出了NUMA(Non-Uniform Memory Access)非均匀内存访问。

中断的问题上,当两个NUMA节点处理中断时,CPU实例化的softnet_data以及驱动分配的sk_buffer都可能是跨Node的,数据接收后对上层应用Redis来说,跨Node访问的几率也大大提高,并且无法充分利用L2、L3 cache,增加了延时。
由于Linux wake affinity特性,如果两个进程频繁互动,调度系统会觉得它们很有可能共享同样的数据,把它们放到同一CPU核心或NUMA Node有助于提高缓存和内存的访问性能,所以当一个进程唤醒另一个的时候,被唤醒的进程可能会被放到相同的CPU core或者相同的NUMA节点上。
在k8s管理容器的组件里,与NUMA有关的组件是拓扑管理器(topologyManager).
实现方案如下:
- resource-exporter 是部署在每个节点上的 DaemonSet,负责节点的拓扑信息采集,并将节点信息写入 CR 中(Numatopology)。
- Volcano 根据节点的 Numatopology,在调度 Pod 时进行 NUMA 调度感知。
- 节点 kubelet 完成绑核工作。
(⎈|kubeasz-test:monitoring)➜ ~ kubectl get numatopologies node5 -o yaml
apiVersion: nodeinfo.volcano.sh/v1alpha1
kind: Numatopology
metadata:
creationTimestamp: "2025-10-26T08:34:49Z"
generation: 1
name: node5
resourceVersion: "26517897"
uid: b0fd84f3-9d97-4df5-b053-9e209f6e6e04
spec:
# cpu的NUMANodeID、SocketID、CoreID的信息
cpuDetail:
"0": {}
"1":
core: 1
"2":
socket: 1
"3":
core: 1
socket: 1
"4":
socket: 2
"5":
core: 1
socket: 2
"6":
socket: 3
"7":
core: 1
socket: 3
"8":
socket: 4
"9":
core: 1
socket: 4
"10":
socket: 5
"11":
core: 1
socket: 5
"12":
socket: 6
"13":
core: 1
socket: 6
"14":
socket: 7
"15":
core: 1
socket: 7
# 资源的NUMA感知信息,包含可分配量和资源总量
numares:
cpu:
capacity: 16
# 包含cpuManager、topologyManager的策略配置。
policies:
CPUManagerPolicy: ""
TopologyManagerPolicy: ""
action
https://volcano.sh/zh/docs/actions/
action中有enqueue、allocate、preempt、reclaim、backfill、shuffle
// https://github.com/volcano-sh/volcano/blob/b27b4bbe7d19e225e75a11e424bee38ec29a4041/pkg/scheduler/actions/factory.go
func init() {
// 注册 action
framework.RegisterAction(reclaim.New()) // 根据队列权重回收队列的资源。
framework.RegisterAction(allocate.New()) // 执行调度操作(分配node)
framework.RegisterAction(backfill.New()) // 回填步骤,处理待调度Pod列表中没有指明资源申请量的Pod调度。 Backfill能够提高集群吞吐量,提高资源利用率。
framework.RegisterAction(preempt.New()) // 抢占资源, 用于处理高优先级调度问题。 可以在同queue或同job中抢占资源。
framework.RegisterAction(enqueue.New()) // 调度器的准备阶段, 判断资源是否满足调度条件
framework.RegisterAction(shuffle.New()) // 根据资源状况重新分配节点
}
active 接口
type Action interface {
// action 名称
Name() string
// Initialize initializes the allocator plugins.
Initialize()
// 执行动作
Execute(ssn *Session)
// UnIntialize un-initializes the allocator plugins.
UnInitialize()
}
Enqueue
Enqueue action筛选符合要求的作业进入待调度队列。当一个Job下的最小资源申请量不能得到满足时,即使为Job下的Pod执行调度动作,Pod也会因为gang约束没有达到而无法进行调度; 经过这个action,任务的状态将由pending变为 inqueue。
allocate
allocate对Queue和Job这两个资源排序, 如果job状态为pending,则会尝试为其分配node资源。
preempt
支持队列内资源抢占。高优先级作业可以抢占同队列内低优先级作业的资源,确保关键任务的及时执行
reclaim
支持队列间的资源回收。当队列资源紧张时,触发资源回收机制。优先回收超出队列deserved值的资源,并结合队列/作业优先级选择合适的牺牲者
backfill
Backfill action 是调度流程中处理BestEffort Pod(即没有指定资源申请量的Pod)的调度步骤。与Allocate action类似,Backfill也会遍历所有节点寻找合适的调度位置,主要区别在于它处理的是没有明确资源申请量的Pod。
在集群中,除了需要明确资源申请的工作负载外,还存在一些对资源需求不明确的工作负载。这些工作负载通常以BestEffort的方式运行,Backfill action负责为这类 Pod寻找合适的调度位置。
云原生混部
云原生混部是指通过云原生的方式将在线业务和离线业务部署在同一个集群。 由于在线业务运行具有明显的波峰波谷特征,因此当在线业务运行在波谷时,离线业务可以利用这部分空闲的资源,当在线业务到达波峰时,通过在线作业优先级控制等手段压制离线作业的运行,保障在线作业的资源使用,从而提升集群的整体资源利用率,同时保障在线业务SLO。
QOS
| Qos等级 | 典型应用场景 | CPU优先级 | Memory优先级 |
|---|---|---|---|
| LC(Latency Critical) | 时延敏感极高的核心在线业务,独占CPU | 独占 | 0 |
| HLS(Highly Latency Sensitive) | 时延敏感极高的在线业务 | 2 | 0 |
| LS(Latency Sensitive) | 时延敏感型的近线业务 | 1 | 0 |
| BE(Best Effort) | 离线的AI、大数据业务,可容忍驱逐 | -1 | 0 |
Volcano提供了native、extend等超卖资源计算和上报模式, native的模式会上报超卖资源至节点的allocatable字段,这样一来在线和离线作业的使用方式是一致的,提升了用户体验 , 而extend模式支持将超卖资源以扩展方式上报至节点,做到和Kubernetes的解耦,
在离线作业通常会使用多种不同维度的资源,因此需要对各个维度的资源设置资源隔离措施,Volcano会通过内核态接口设置CPU、Memory、Network等维度的资源隔离,当在离线作业发生资源争用时,压制离线作业的资源使用,优先保障在线作业QoS。
CPU: OS层面提供了5级CPU QoS等级,数值从-2到2,QoS等级越高则代表可以获得更多的CPU时间片并有更高的抢占优先级。通过设置cpu子系统的cgroup cpu.qos_level可以为不同业务设置不用的CPU QoS。
Memory: Memory隔离体现在系统发生OOM时离线作业会被有限OOM Kill掉,通过设置memory子系统的cgroup memory.qos_level可以为不同业务设置不同的Memory QoS。
Network: 网络隔离实现了对在线作业的出口网络带宽保障,它基于整机的带宽大小,并通过cgroup + tc + ebpf技术,实现在线作业对离线作业的出口网络带宽压制。
CRD
(⎈|kubeasz-test:volcano-system)➜ ~ kubectl api-resources| head -1;kubectl api-resources |grep volcano
NAME SHORTNAMES APIVERSION NAMESPACED KIND
jobs vcjob,vj batch.volcano.sh/v1alpha1 true Job
commands bus.volcano.sh/v1alpha1 true Command
jobflows jf flow.volcano.sh/v1alpha1 true JobFlow
jobtemplates jt flow.volcano.sh/v1alpha1 true JobTemplate
numatopologies numatopo nodeinfo.volcano.sh/v1alpha1 false Numatopology
podgroups pg,podgroup-v1beta1 scheduling.volcano.sh/v1beta1 true PodGroup
queues q,queue-v1beta1 scheduling.volcano.sh/v1beta1 false Queue
hypernodes hn topology.volcano.sh/v1alpha1 false HyperNode
PodGroup
https://volcano.sh/zh/docs/v1-12-0/podgroup/
PodGroup 一组相关的 Pod 集合。这主要解决了 Kubernetes 原生调度器中单个 Pod 调度的限制。
Volcano Job(vcjob)
https://volcano.sh/zh/docs/v1-12-0/vcjob/
区别于Kubernetes Job,vcjob提供了更多高级功能,如可指定调度器、支持最小运行pod数、 支持task、支持生命周期管理、支持指定队列、支持优先级调度等。 Volcano Job更加适用于机器学习、大数据、科学计算等高性能计算场景。
queue
https://volcano.sh/zh/docs/v1-12-0/queue/ Queue是Volcano调度系统中的核心概念,用于管理和分配集群资源。 它充当了资源池的角色,允许管理员将集群资源划分给不同的用户组或应用场景。该自定义资源可以很好地用于多租户场景下的资源隔离
queue是容纳一组podgroup的队列.volcano启动后,会默认创建名为default的queue,weight为1。后续下发的job,若未指定queue,默认属于default queue

# default queue
(⎈|kubeasz-test:volcano-system)➜ ~ kubectl get queue default -o yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2025-07-26T02:38:24Z"
generation: 2
name: default
resourceVersion: "16927137"
uid: b3816aae-d77e-4576-8699-eed4d0324848
spec:
guarantee: {}
parent: root
reclaimable: true
weight: 1
status:
allocated:
cpu: "3"
memory: "0"
pods: "3"
reservation: {}
state: Open
# root的queue,该queue为开启层级队列功能时使用,作为所有队列的根队列,default queue为root queue的子队列
(⎈|kubeasz-test:volcano-system)➜ ~ kubectl get queue root -o yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
creationTimestamp: "2025-07-26T02:38:24Z"
generation: 786
name: root
resourceVersion: "17202849"
uid: 8399648f-7082-49a1-98ec-7fb9c1138172
spec:
deserved:
attachable-volumes-csi-local.csi.openebs.io: 12884901882m
cpu: 92400m
ephemeral-storage: "381412259579"
hugepages-2Mi: "0"
kubernetes.io/batch-cpu: "46335"
kubernetes.io/batch-memory: "38576847428"
kubernetes.io/mid-cpu: "11076"
kubernetes.io/mid-memory: "10040600338"
memory: 96480436Ki
pods: "660"
guarantee:
resource:
cpu: "0"
memory: "0"
reclaimable: false
weight: 1
status:
allocated:
cpu: "3"
memory: "0"
pods: "3"
reservation: {}
state: Open