Watch 实现原理及 etcd 源码分析
问题
client-go实现一个监听deployments 变化的功能,如何判断kubernetes资源的变化?
有两个与kubernetes资源对象相关的属性。
- ResourceVersion 基于底层etcd的revision机制,资源对象每次update时都会改变,且集群范围内唯一。
- Generation初始值为1,随Spec内容的改变而自增
(⎈|docker-desktop:N/A)➜ kubectl get deploy coredns -n kube-system -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
deployment.kubernetes.io/revision: "1"
creationTimestamp: "2024-10-26T07:17:26Z"
generation: 1
labels:
k8s-app: kube-dns
name: coredns
namespace: kube-system
resourceVersion: "552990"
uid: a33037b1-aa9f-49b6-872b-31dedad4f297
resourceVersion的维护其实是利用了底层存储etcd的Revision机制.
ETCD共四种version
| 字段 | 作用范围 | 说明 |
|---|---|---|
| Version | key | 单个Key的修改次数,单调递增 |
| Revision | 全局 | Key在集群中的全局版本号,全局唯一 |
| ModRevision | key | Key 最后一次修改时的 Revision |
| CreateRevision | 全局 | Key 创建时的 Revision |
the Revision is the current revision of etcd. It is incremented every time the v3 backed is modified (e.g., Put, Delete, Txn). ModRevision is the etcd revision of the last update to a key. Version is the number of times the key has been modified since it was created. Get(…, WithRev(rev)) will perform a Get as if the etcd store is still at revision rev.
(⎈|docker-desktop:N/A)➜ rm -rf /tmp/etcd-data.tmp && mkdir -p /tmp/etcd-data.tmp && \
docker rmi quay.io/coreos/etcd:v3.5.1 || true && \
docker run \
-d \
-p 2379:2379 \
-p 2380:2380 \
--mount type=bind,source=/tmp/etcd-data.tmp,destination=/etcd-data \
--name etcd-gcr-v3.5.1 \
quay.io/coreos/etcd:v3.5.1 \
/usr/local/bin/etcd \
--name s1 \
--data-dir /etcd-data \
--listen-client-urls http://0.0.0.0:2379 \
--advertise-client-urls http://0.0.0.0:2379 \
--listen-peer-urls http://0.0.0.0:2380 \
--initial-advertise-peer-urls http://0.0.0.0:2380 \
--initial-cluster s1=http://0.0.0.0:2380 \
--initial-cluster-token tkn \
--initial-cluster-state new \
--log-level info \
--logger zap \
--log-outputs stderr
(⎈|docker-desktop:N/A)➜ etcdctl put k1 v1
OK
(⎈|docker-desktop:N/A)➜ etcdctl get k1 -w json|jq
{
"header": {
"cluster_id": 18011104697467367000,
"member_id": 6460912315094811000,
"revision": 2,
"raft_term": 2
},
"kvs": [
{
"key": "azE=",
"create_revision": 2,
"mod_revision": 2,
"version": 1,
"value": "djE="
}
],
"count": 1
}
(⎈|docker-desktop:N/A)➜ etcdctl put k2 v2
OK
(⎈|docker-desktop:N/A)➜ etcdctl get k2 -w json|jq
{
"header": {
"cluster_id": 18011104697467367000,
"member_id": 6460912315094811000,
"revision": 3,
"raft_term": 2
},
"kvs": [
{
"key": "azI=",
"create_revision": 3,
"mod_revision": 3,
"version": 1,
"value": "djI="
}
],
"count": 1
}
(⎈|docker-desktop:N/A)➜ etcdctl put k1 nv1
OK
(⎈|docker-desktop:N/A)➜ etcdctl get k1 -w json|jq
{
"header": {
"cluster_id": 18011104697467367000,
"member_id": 6460912315094811000,
"revision": 4,
"raft_term": 2
},
"kvs": [
{
"key": "azE=",
"create_revision": 2,
"mod_revision": 4,
"version": 2,
"value": "bnYx"
}
],
"count": 1
}
(⎈|docker-desktop:N/A)➜ etcdctl get k2 -w json|jq
{
"header": {
"cluster_id": 18011104697467367000,
"member_id": 6460912315094811000,
"revision": 4,
"raft_term": 2
},
"kvs": [
{
"key": "azI=",
"create_revision": 3,
"mod_revision": 3,
"version": 1,
"value": "djI="
}
],
"count": 1
}
(⎈|docker-desktop:N/A)➜ etcdctl del k1
1
(⎈|docker-desktop:N/A)➜ etcdctl get k1 -w json|jq
{
"header": {
"cluster_id": 18011104697467367000,
"member_id": 6460912315094811000,
"revision": 5,
"raft_term": 2
}
}
(⎈|docker-desktop:N/A)➜ etcdctl get k1 --rev=2 -w json|jq
{
"header": {
"cluster_id": 18011104697467367000,
"member_id": 6460912315094811000,
"revision": 5,
"raft_term": 2
},
"kvs": [
{
"key": "azE=",
"create_revision": 2,
"mod_revision": 2,
"version": 1,
"value": "djE="
}
],
"count": 1
}
(⎈|docker-desktop:N/A)➜ etcdctl put k1 dnv1
OK
(⎈|docker-desktop:N/A)➜ etcdctl get k1 -w json|jq
{
"header": {
"cluster_id": 18011104697467367000,
"member_id": 6460912315094811000,
"revision": 6,
"raft_term": 2
},
"kvs": [
{
"key": "azE=",
"create_revision": 6,
"mod_revision": 6,
"version": 1,
"value": "ZG52MQ=="
}
],
"count": 1
}
client获取事件的机制,etcd是使用轮询模式还是推送模式呢?两者各有什么优缺点?

然而当你的watcher成千上万的时,即使集群空负载,大量轮询也会产生一定的QPS,server端会消耗大量的socket、内存等资源,导致etcd的扩展性、稳定性无法满足Kubernetes等业务场景诉求。
在etcd v3中,为了解决etcd v2的以上缺陷,使用的是基于HTTP/2的gRPC协议,双向流的Watch API设计,实现了连接多路复用.
在 clientv3 库中,Watch 特性被抽象成 Watch、Close、RequestProgress 三个简单 API 提供给开发者使用,屏蔽了 client 与 gRPC WatchServer 交互的复杂细节,实现了一个 client 支持多个 gRPC Stream,一个 gRPC Stream 支持多个 watcher,显著降低了你的开发复杂度。
client端的实现
// https://github.com/etcd-io/etcd/blob/8194aa3f03333d099b6b57a571ead092cd0f4553/clientv3/watch.go
type Watcher interface {
Watch(ctx context.Context, key string, opts ...OpOption) WatchChan
RequestProgress(ctx context.Context) error
Close() error
}
事件是如何存储的? 会保留多久?watch命令中的版本号具有什么作用?
etcd经历了从滑动窗口到MVCC机制的演变,滑动窗口是仅保存有限的最近历史版本到内存中,而MVCC机制则将历史版本保存在磁盘中,避免了历史版本的丢失,极大的提升了Watch机制的可靠性。
当client和server端出现短暂网络波动等异常因素后,导致事件堆积时,server端会丢弃事件吗?若你监听的历史版本号server端不存在了,你的代码该如何处理?
可靠事件推送机制: 将可靠的事件推送机制拆分成最新事件推送、异常场景重试、历史事件推送机制三个子问题来进行分析,下面详细讲解.
如果你创建了上万个watcher监听key变化,当server端收到一个写请求后,etcd是如何根据变化的key快速找到监听它的watcher呢?

当产生一个事件时,etcd首先需要从map查找是否有watcher监听了单key,其次它还需要从区间树找出与此key相交的所有区间,然后从区间的值获取监听的watcher集合。
可靠事件推送机制的三个子问题
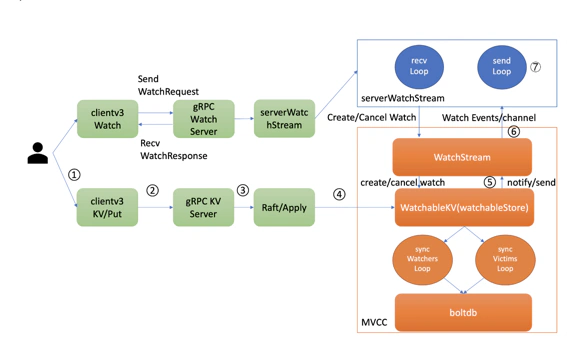
最新事件

当你创建完成 watcher 后,此时你执行 put hello 修改操作时,如上图所示,请求经过 KVServer、Raft 模块后 Apply 到状态机时,在 MVCC 的 put 事务中,它会将本次修改的后的 mvccpb.KeyValue 保存到一个 changes 数组中。
// https://github.com/etcd-io/etcd/blob/34bd797e6754911ee540e8c87f708f88ffe89f37/mvcc/watchable_store_txn.go
func (tw *watchableStoreTxnWrite) End() {
changes := tw.Changes()
if len(changes) == 0 {
tw.TxnWrite.End()
return
}
rev := tw.Rev() + 1
evs := make([]mvccpb.Event, len(changes))
for i, change := range changes {
evs[i].Kv = &changes[i]
if change.CreateRevision == 0 {
evs[i].Type = mvccpb.DELETE
evs[i].Kv.ModRevision = rev
} else {
evs[i].Type = mvccpb.PUT
}
}
// end write txn under watchable store lock so the updates are visible
// when asynchronous event posting checks the current store revision
tw.s.mu.Lock()
tw.s.notify(rev, evs)
tw.TxnWrite.End()
tw.s.mu.Unlock()
}
func (s *watchableStore) notify(rev int64, evs []mvccpb.Event) {
var victim watcherBatch
for w, eb := range newWatcherBatch(&s.synced, evs) {
if eb.revs != 1 {
if s.store != nil && s.store.lg != nil {
s.store.lg.Panic(
"unexpected multiple revisions in watch notification",
zap.Int("number-of-revisions", eb.revs),
)
} else {
plog.Panicf("unexpected multiple revisions in notification")
}
}
if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: rev}) {
pendingEventsGauge.Add(float64(len(eb.evs)))
} else { // 如果 channel buffer 进入下面流程
// move slow watcher to victims
w.minRev = rev + 1
if victim == nil {
victim = make(watcherBatch)
}
w.victim = true
victim[w] = eb
s.synced.delete(w) // 此 watcher 从 synced watcherGroup 中删除
slowWatcherGauge.Inc()
}
}
s.addVictim(victim)
}
在 put 事务结束时,如下面的精简代码所示,它会将 KeyValue 转换成 Event 事件,然后回调 watchableStore.notify 函数(流程 5)。notify 会匹配出监听过此 key 并处于 synced watcherGroup 中的 watcher,同时事件中的版本号要大于等于 watcher 监听的最小版本号,才能将事件发送到此 watcher 的事件 channel 中。
异常场景重试机制
若出现 channel buffer 满了,etcd 为了保证 Watch 事件的高可靠性,并不会丢弃它,而是将此 watcher 从 synced watcherGroup 中删除,然后将此 watcher 和事件列表保存到一个名为受害者 victim 的 watcherBatch 结构中,通过异步机制重试保证事件的可靠性
历史事件推送机制
// syncWatchers syncs unsynced watchers by:
// 1. choose a set of watchers from the unsynced watcher group
// 2. iterate over the set to get the minimum revision and remove compacted watchers
// 3. use minimum revision to get all key-value pairs and send those events to watchers
// 4. remove synced watchers in set from unsynced group and move to synced group
func (s *watchableStore) syncWatchers() int {
s.mu.Lock()
defer s.mu.Unlock()
if s.unsynced.size() == 0 {
return 0
}
s.store.revMu.RLock()
defer s.store.revMu.RUnlock()
// in order to find key-value pairs from unsynced watchers, we need to
// find min revision index, and these revisions can be used to
// query the backend store of key-value pairs
curRev := s.store.currentRev
compactionRev := s.store.compactMainRev
wg, minRev := s.unsynced.choose(maxWatchersPerSync, curRev, compactionRev)
minBytes, maxBytes := newRevBytes(), newRevBytes()
revToBytes(revision{main: minRev}, minBytes)
revToBytes(revision{main: curRev + 1}, maxBytes)
// UnsafeRange returns keys and values. And in boltdb, keys are revisions.
// values are actual key-value pairs in backend.
tx := s.store.b.ReadTx()
tx.RLock()
// 最小版本号作为开始区间,当前 server 最大版本号作为结束区间
revs, vs := tx.UnsafeRange(keyBucketName, minBytes, maxBytes, 0)
var evs []mvccpb.Event
if s.store != nil && s.store.lg != nil {
evs = kvsToEvents(s.store.lg, wg, revs, vs)
} else {
// TODO: remove this in v3.5
evs = kvsToEvents(nil, wg, revs, vs)
}
tx.RUnlock()
var victims watcherBatch
wb := newWatcherBatch(wg, evs)
for w := range wg.watchers {
w.minRev = curRev + 1
eb, ok := wb[w]
if !ok {
// bring un-notified watcher to synced
s.synced.add(w)
s.unsynced.delete(w)
continue
}
if eb.moreRev != 0 {
w.minRev = eb.moreRev
}
if w.send(WatchResponse{WatchID: w.id, Events: eb.evs, Revision: curRev}) {
pendingEventsGauge.Add(float64(len(eb.evs)))
} else {
if victims == nil {
victims = make(watcherBatch)
}
w.victim = true
}
if w.victim {
victims[w] = eb
} else {
if eb.moreRev != 0 {
// stay unsynced; more to read
continue
}
s.synced.add(w)
}
s.unsynced.delete(w)
}
s.addVictim(victims)
vsz := 0
for _, v := range s.victims {
vsz += len(v)
}
slowWatcherGauge.Set(float64(s.unsynced.size() + vsz))
return s.unsynced.size()
}
syncWatchersLoop,它会遍历处于 unsynced watcherGroup 中的每个 watcher,为了优化性能,它会选择一批 unsynced watcher 批量同步,找出这一批 unsynced watcher 中监听的最小版本号。
因 boltdb 的 key 是按版本号存储的,因此可通过指定查询的 key 范围的最小版本号作为开始区间,当前 server 最大版本号作为结束区间,遍历 boltdb 获得所有历史数据
然后将 KeyValue 结构转换成事件,匹配出监听过事件中 key 的 watcher 后,将事件发送给对应的 watcher 事件接收 channel 即可。发送完成后,watcher 从 unsynced watcherGroup 中移除、添加到 synced watcherGroup 中